

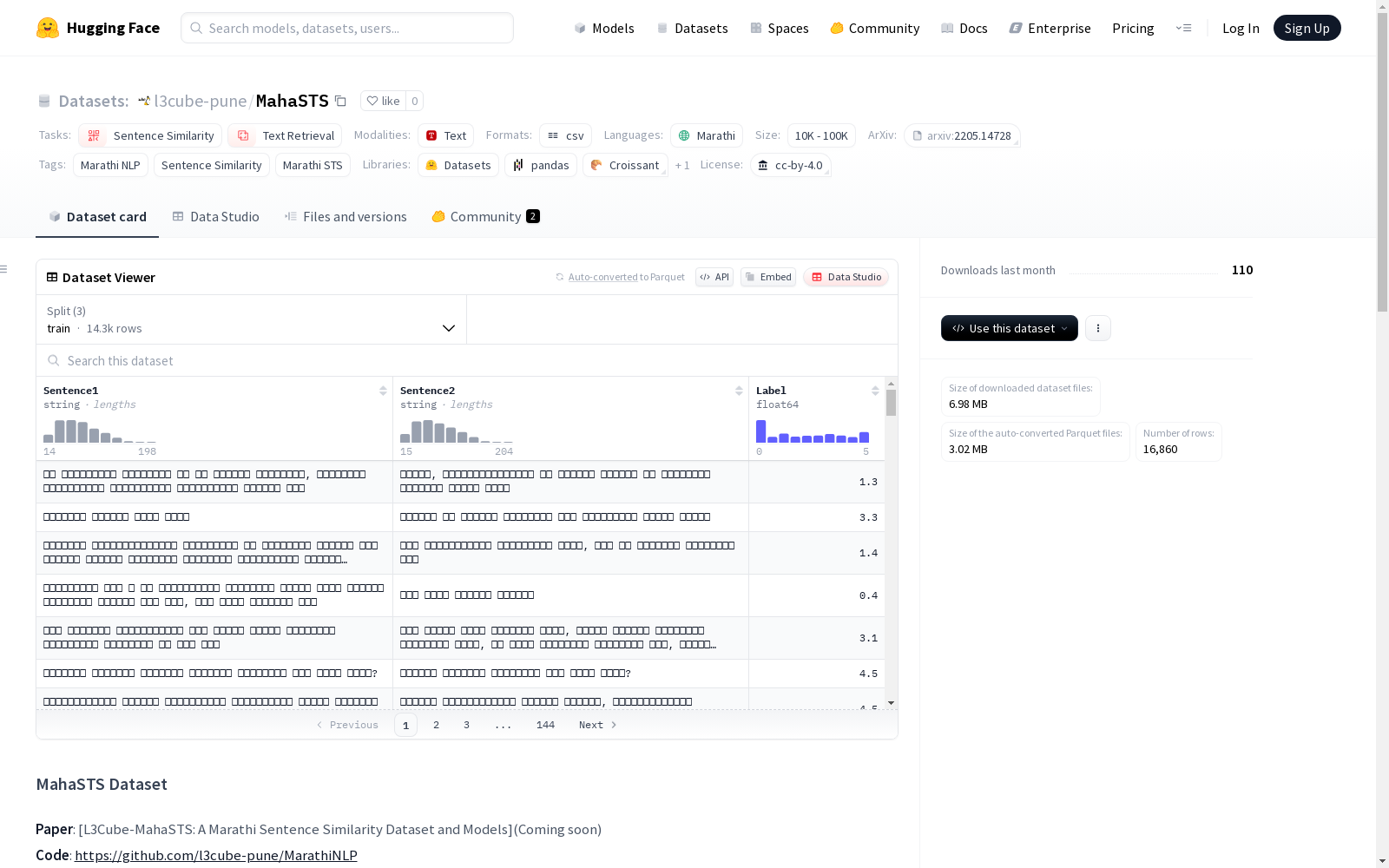
印度理工学院马德拉斯分校 本次发布的数据集 L3Cube-MahaSTS, L3Cube-MahaSTS是一个人类标注的马拉地语句子文本相似度数据集,包含16,860个马拉地语句对,每个语句对都被标注了0到5之间的连续相似度分数。数据集被均匀地分布在六个基于分数的桶中,以确保监督平衡并减少标签偏差。该数据集旨在支持马拉地语中细粒度语义相似度建模,并促进低资源环境中模型训练的稳定性和泛化能力。
Dataset card 内容:
Files and versions 内容:
关于 印度理工学院马德拉斯分校 , 印度理工学院马德拉斯分校是位于印度的一所著名研究型大学,是印度理工学院系统中的一员,以其在工程、科学和技术领域的教育和研究而闻名。_simple
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)