

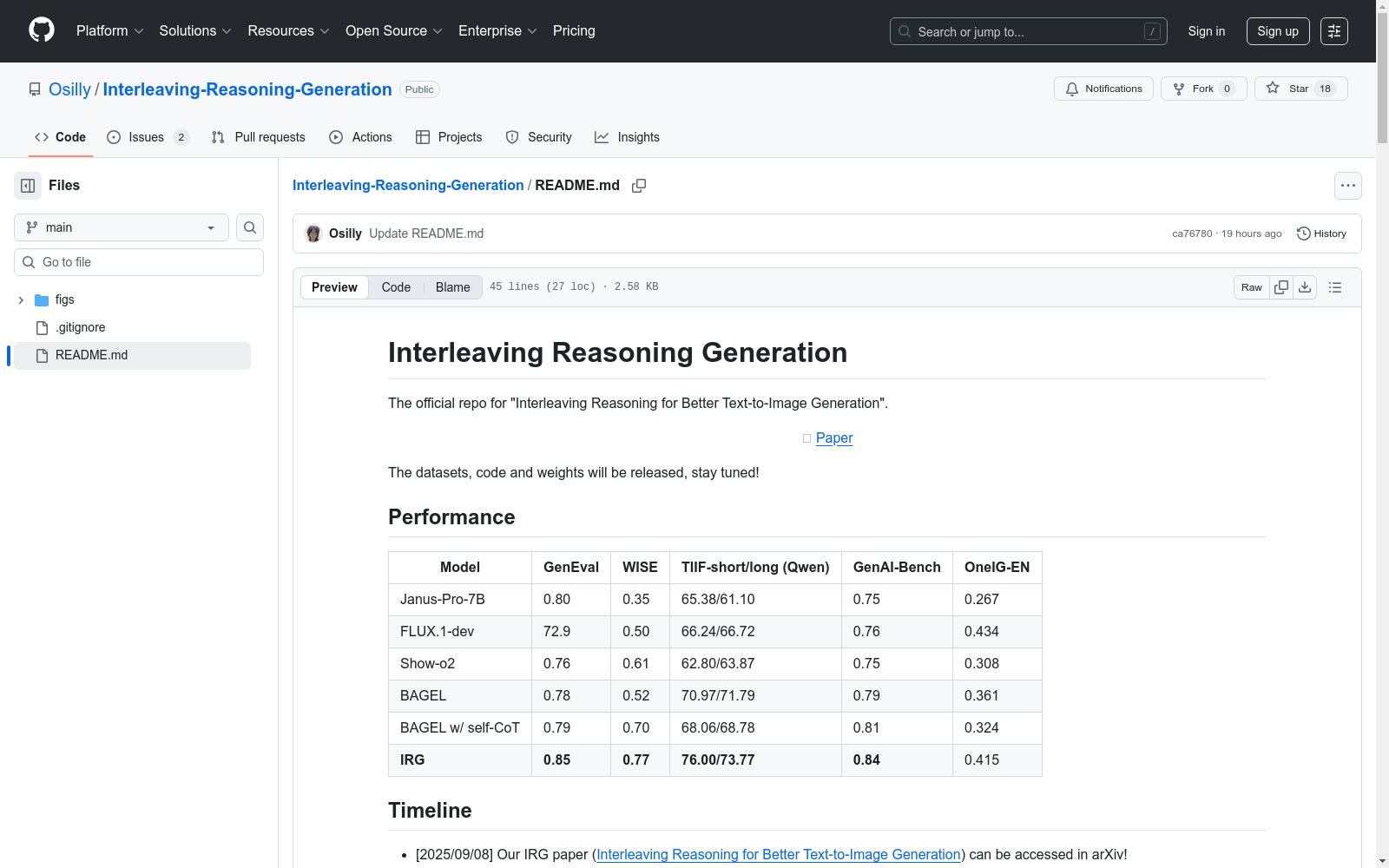
华东师范大学 本次发布的数据集 IRGL-300K, IRGL-300K是一个包含300,000条数据的数据集,由华东师范大学、香港中文大学、小红书、加州大学洛杉矶分校、浙江大学、牛津大学的研究人员共同创建。该数据集旨在用于训练一个名为Interleaving Reasoning Generation (IRG)的文本到图像生成模型。数据集包括六个分解的学习模式,共同覆盖了基于文本的思考和完整的思考-图像轨迹。数据集的创建过程包括两个阶段的训练,首先建立强大的思考和反思,然后利用完整的思考-图像轨迹数据有效地调整IRG流程。IRG在多个基准测试中取得了最先进的性能,并在视觉质量和细粒度保真度方面取得了显著的改进。
README 内容:
关于 华东师范大学 , -_simple
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)