

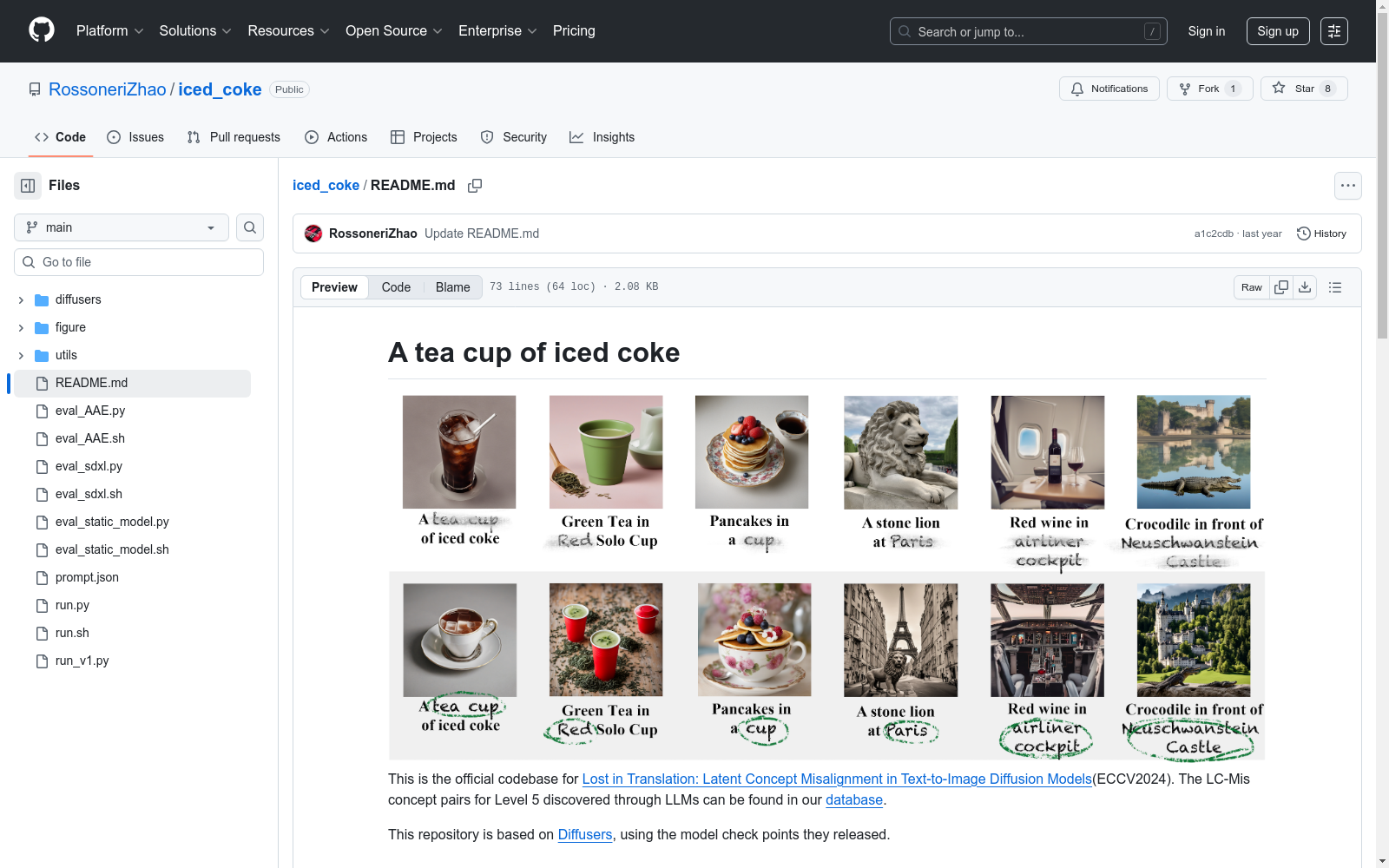
本次发布的数据集 LC-Mis Dataset, 该数据集专为探究文本到图像生成模型中潜在的Concept Misalignment问题而设计,其中包含272个高质量的概念对。在这些概念对中,有173对专门针对潜在的Concept Misalignment。该数据集规模宏大,包含2,495个基于句子的文本提示,进而生成了9,980张图像。其任务旨在评估并减少文本到图像生成过程中的潜在概念不一致问题。
README 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)