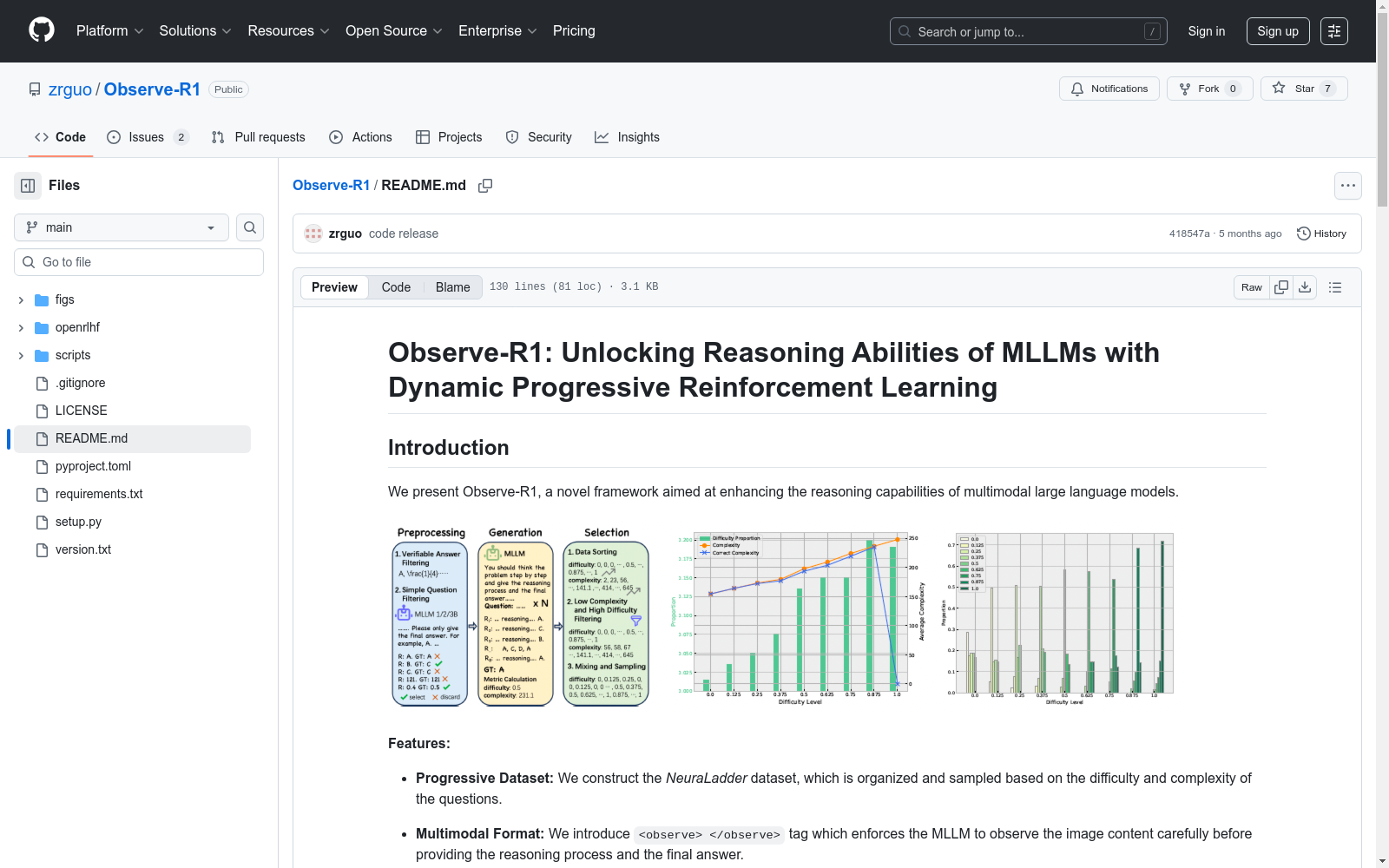
本次发布的数据集 NeuraLadder, 该数据集是根据强化学习训练在多模态大型语言模型中的数据样本难度和复杂性进行组织和采样的。它旨在支持渐进式学习方法,使模型能够逐步推理和渐进学习。该数据集的任务是提升模型在推理能力方面的强化学习训练。
README 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。


本次发布的数据集 NeuraLadder, 该数据集是根据强化学习训练在多模态大型语言模型中的数据样本难度和复杂性进行组织和采样的。它旨在支持渐进式学习方法,使模型能够逐步推理和渐进学习。该数据集的任务是提升模型在推理能力方面的强化学习训练。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。


面向社区/商业的数据集话题

面向高校/科研机构的开源数据集话题
_1769672084863.jpg)