

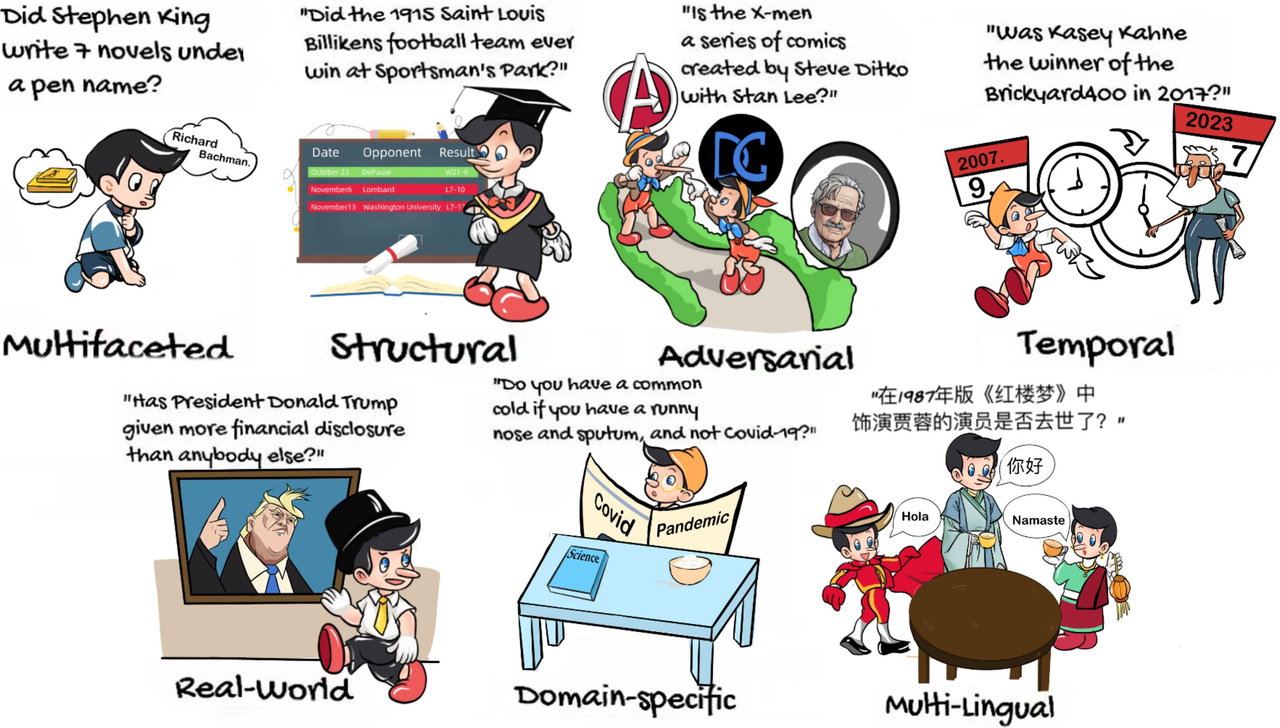
Pinocchio数据集由清华大学、伊利诺伊大学芝加哥分校和剑桥大学的研究人员联合创建,旨在全面评估大型语言模型(LLMs)在事实知识存储与推理能力方面的表现。该数据集包含了20,000个多样化的事实问题,这些问题覆盖了不同的来源、时间线、领域、地区和语言。数据集涵盖了7个不同的任务来测试LLMs在多事实推理、处理结构化与非结构化知识、识别细微事实差异、抵抗对抗性示例等方面的能力。Pinocchio为研究人员提供了一个强大的工具,以理解模型在多个维度上的能力,并促进LLMs在事实知识方面的发展。
首页 / 开源数据市场 / 正文
【五号雷达-数据快讯】Pinocchio - 事实知识评估数据集
五号雷达开源数据市场2024-03-27 13:3757
Pinocchio为研究人员提供了一个强大的工具,以理解模型在多个维度上的能力,并促进LLMs在事实知识方面的发展。

社区讨论
近期热门


_1769672084863.jpg)