

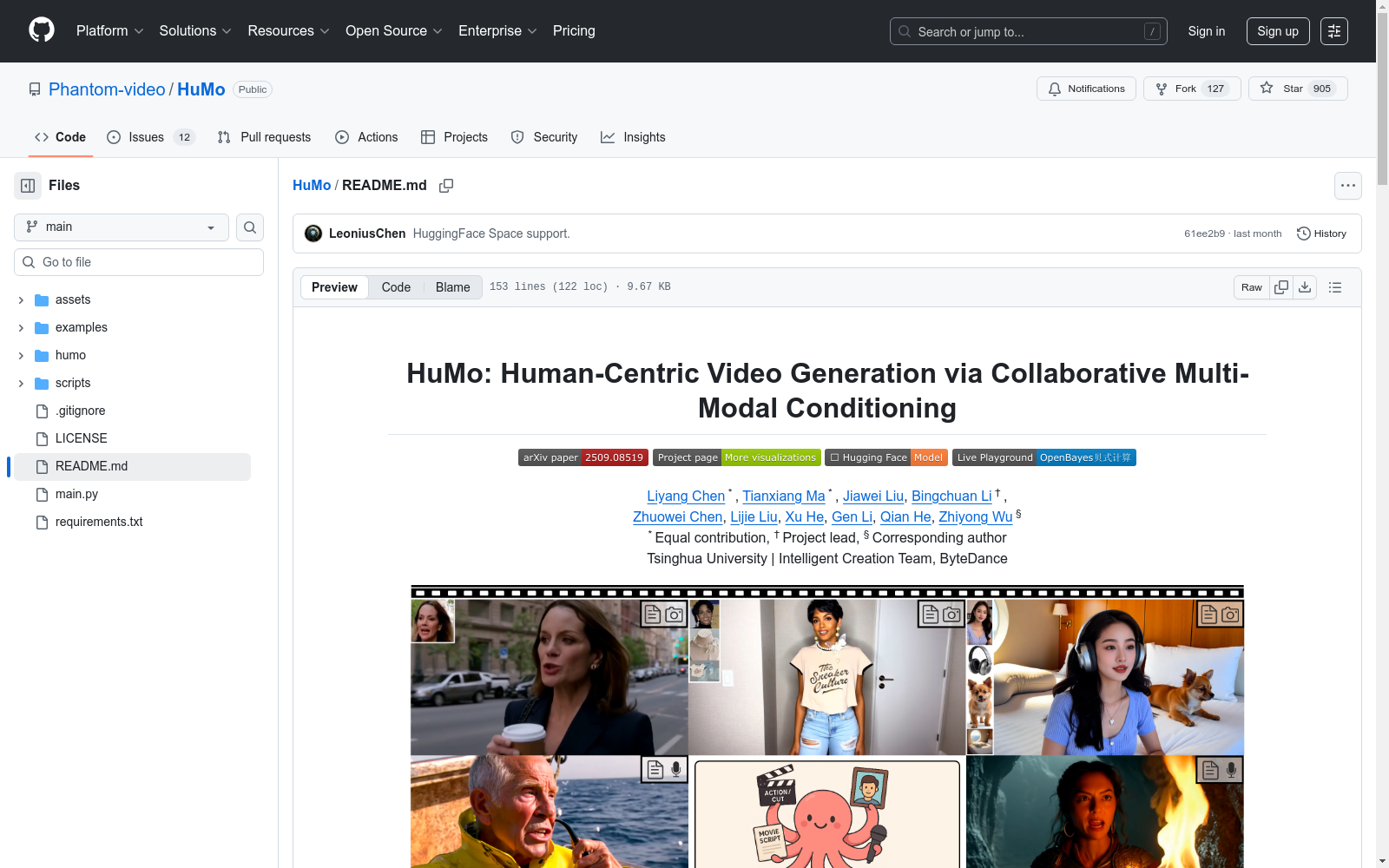
清华大学 本次发布的数据集 HuMo, HuMo数据集是一个高质量的多模态数据集,包含文本、参考图像和音频三种模态的配对三元组条件。数据集构建经过两阶段的多模态数据处理流程,首先从大规模视频样本中检索与视频语义相同但视觉属性不同的参考图像,其次通过语音增强和语音-唇对齐估计进一步筛选具有同步音频轨道的视频样本。数据集的构建为后续多模态视频生成模型的学习提供了坚实的基础,旨在解决人本视频生成中数据稀缺和多模态协同控制困难的问题。
README 内容:
关于 清华大学 , 清华大学是中国的一所综合性研究型大学,位于北京,是中国最高学府之一,具有很高的国际声誉。学校拥有丰富的教学资源和强大的科研实力,在多个学科领域取得了世界领先的研究成果。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)