

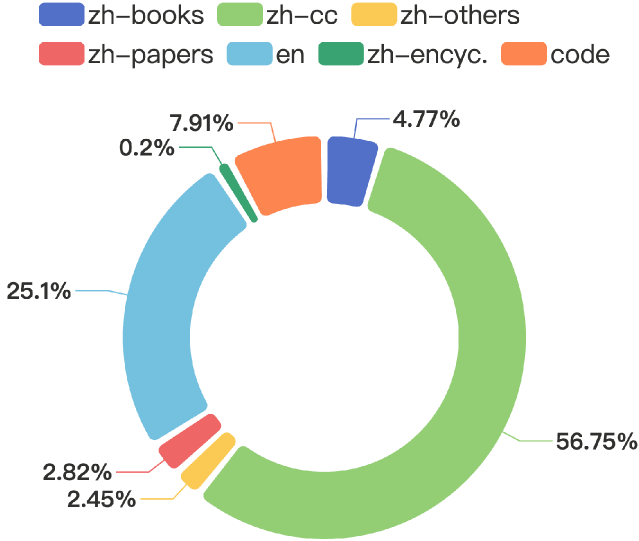
MAP-CC(Massive Appropriate Pretraining Chinese Corpus)数据集由Multimodal Art Projection 、复旦大学、北京大学等机构共同研发,是一个大规模的开源中文预训练数据集。该数据集包含800亿个Token,由多个子集组成,每个子集都来自不同的数据源,如:博客、新闻文章、中文百科全书、中文学术论文、中文图书等。MAP-CC通过精心设计的数据清洗和筛选流程,提高了中文网络语料库的质量,为学术界和工业界提供了高质量的中文预训练数据和有效的数据准备方法。该数据集的构建突破了传统以英文数据为主的训练模式,为非英语语言特别是中文的深度学习和理解能力提供了新的研究范式。
详情请参见五号雷达:https://www.5radar.com/result?key=MAP-CC



_1769672084863.jpg)