

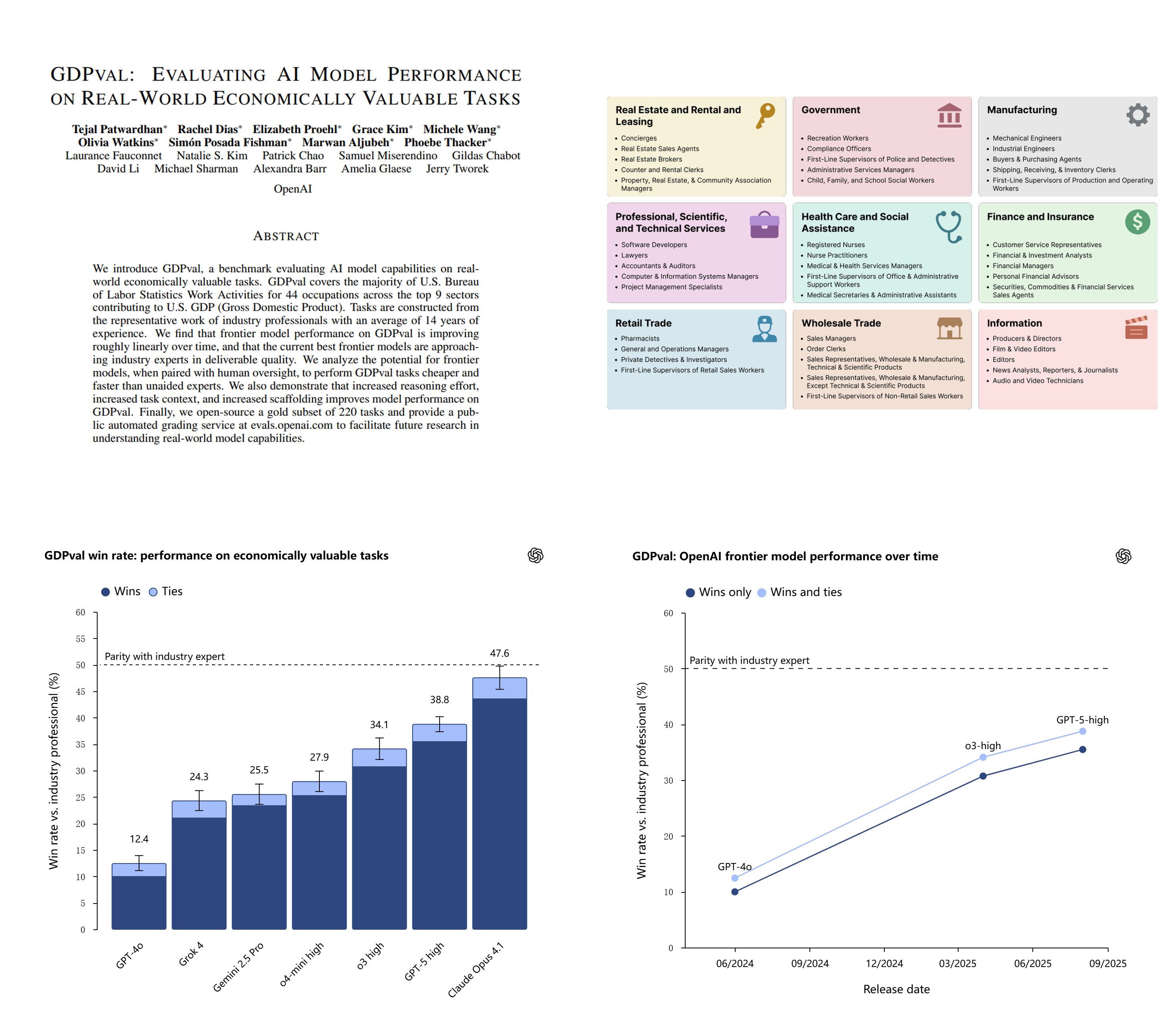
OpenAI发布的论文 《GDPVAL: Evaluating AI Model Performance on Real-World Economically Valuable Tasks》 ,将大模型评测重心从传统的问答测试,转向真实工作场景。论文提出的 GDPval 评测基准,试图回答一个直观却关键的问题:大模型,究竟能不能胜任现实中的专业工作?
1. 首创经济价值导向
GDPval以具有经济价值的真实职业任务为评测核心,首次系统性地衡量大模型的实际工作能力。评测聚焦对美国 GDP 贡献度最高的 9 个核心行业(如金融、医疗、科技等),并在行业中选取薪酬规模占比最高、且工作内容高度数字化的 44 种职业。
2. 还原真实工作路
在完整基准中,GDPval 共包含了 1,320个评测任务,每个职业对应 30个任务,涵盖财务分析、合同审查、行业研究等典型工作场景。不同于只依赖文本提示词的传统评测,GDPval 为每个任务提供完整的业务资料和附件,模型需按任务要求提交文档、幻灯片、图表、多媒体等成果。
3. 专家闭环评审
这些任务由平均拥有14年行业经验的专家设计,并由同领域的专业评分员在盲测条件下,对模型输出与人类成果进行对比评估。每项任务平均需经历约5轮人工评审与自动化校验的交叉验证,从而更客观地检验模型在真实工作任务中的表现。
基于上述评测设计,OpenAI 对模型表现进行了系统分析。结果显示,处于技术前沿的大语言模型(如 Claude Opus 4.1 和 GPT-5)在 GDPval 评估中整体表现稳定,评测结果能够较好反映其在真实职业任务中的实际工作能力。尤其是引入人类监督后,前沿模型在完成这些专业任务时已在成本与效率上展现出明显优势。研究还表明,更强的推理能力、更丰富的上下文信息,以及更完善的支架式教学(scaffolding),都会显著提升模型在 GDPval 上的表现,使其逐步接近人类专家水平。
OpenAI 对外开源了 GDPval 的“黄金子集”
该数据集由 44 种职业、每类 5 个代表性任务组成,共计 220 个高质量评测任务。数据集中每一行都对应一个具体任务,主要字段包括任务 ID(task_id)、所属行业(sector)、职位名称(occupation)、大模型提示词(prompt),以及配套的参考附件(reference_files)。
数据集地址:GDPval
接下来,小编将带大家具体看一下其中一个评测任务。
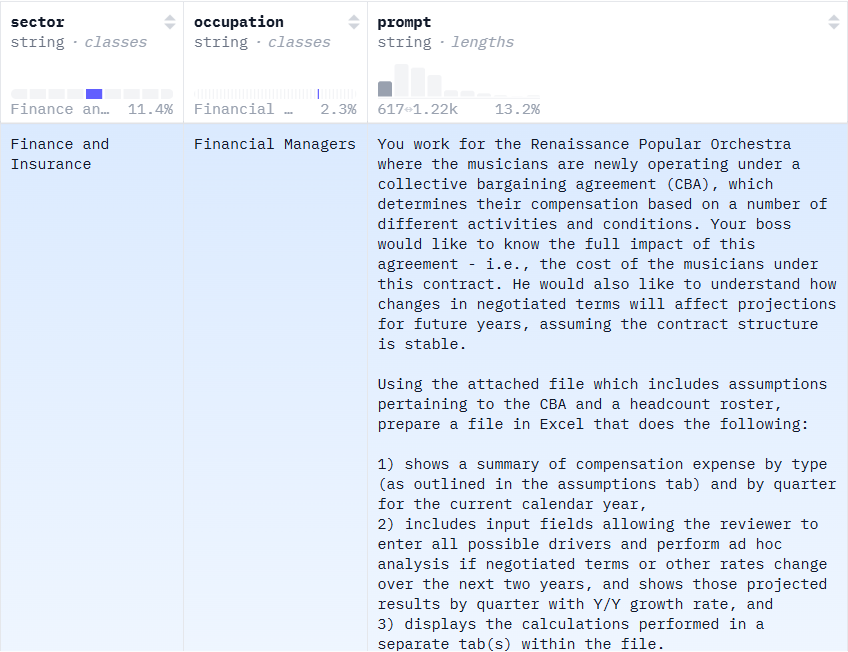
这个任务来自金融与保险行业,对应的职业角色为财务经理,提供给大模型的任务指令如下:
“你就职于文艺复兴流行乐团。该乐团的音乐家近期开始执行一项集体谈判协议(CBA),该协议将根据不同的演出活动及相关条件来确定其薪酬。你的上司希望全面了解这份协议所带来的影响,比如:在该合同框架下音乐家的整体薪酬成本。他还希望了解,在合同结构保持稳定的前提下,谈判条款发生变化将如何影响未来的成本预测结果。
请基于所附Excel文件(包含与 CBA 相关的假设条件及人员名册),在 Excel中实现以下功能:
1. 以薪酬类型和季度为维度,汇总本年度的薪酬支出情况。
2. 设置可输入参数,允许查看者调整所有可能的驱动因素,在未来两年内谈判条款或其他费率发生变化时进行灵活分析,并按季度展示预测结果及同比增长率。
3. 在单独的工作表中展示所执行的各项计算过程。”
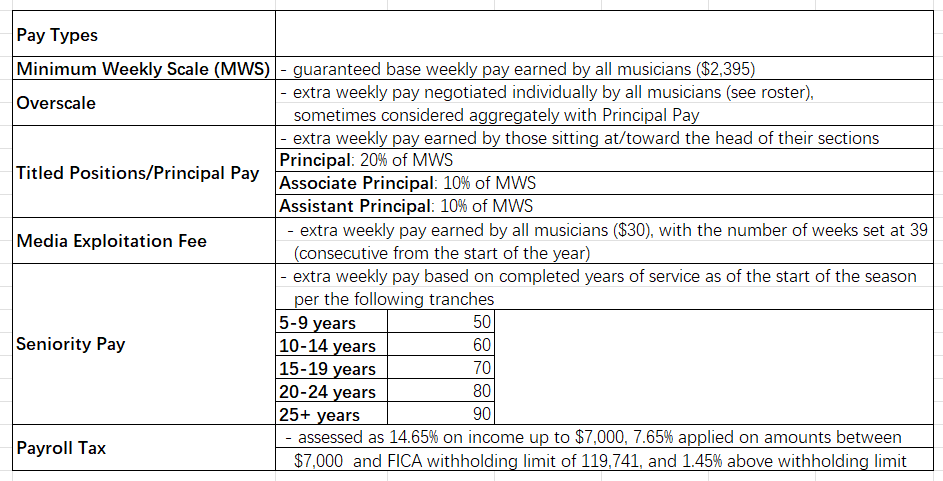
指令附件是一份 Excel 文件,包含薪酬结构表与人员名册表两部分。薪酬结构表明确了音乐家薪酬的构成及计算规则,涵盖最低周薪标准、超标准薪酬、首席岗位薪酬、媒体使用补偿、工龄补贴、以及薪资税。
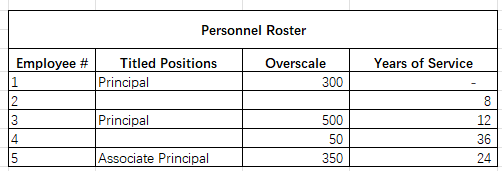
人员名册表记录了每位音乐家的岗位头衔、个人协商的超标准薪酬、工作年限及备注信息。
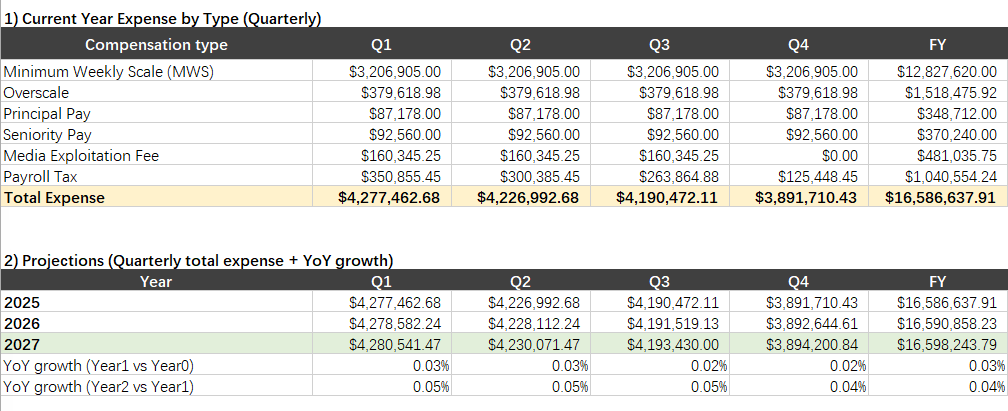
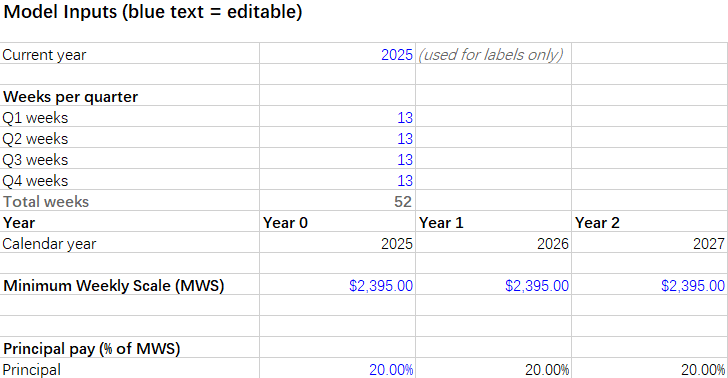
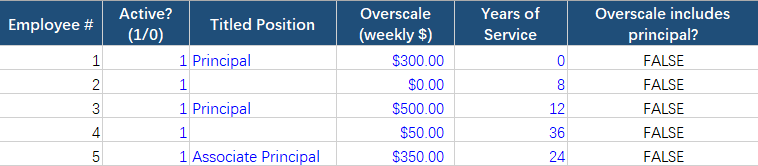
小编将同一段提示词及Excel 附件一并输入 ChatGPT 5.2 对话框中,模型仅在2分钟内完成解析与计算,并生成了可供下载的 Excel 文件。该文件在原有薪酬结构假设表和人员名册表的基础上,新增了 6 张工作表,分别为结果汇总表、参数输入表、人员配置表、薪酬费率计算表、税费计算表和汇总计算表。
其中,结果汇总表用于集中展示测算结果,按薪酬类型汇总各季度的用工成本,并给出未来两年的季度预测及同比增长率。
参数输入表用于集中设置可变参数,支持对关键假设进行灵活调整,从而开展多情景的薪酬成本分析。
人员配置表在人员层面提供灵活调整空间,通过“是否纳入测算”字段控制个体是否参与计算,并支持动态调整岗位类型、超额薪酬水平、工作年限,以及是否将首席岗位薪酬计入超额薪酬。
具体计算过程被拆分至薪酬费率计算表、税费计算表和汇总计算表,用于完成费率换算、税费测算与最终汇总。
综合来看,在该任务中,ChatGPT 5.2 能够在较短时间内完成完整的业务理解与结构化建模,并输出逻辑清晰、可追溯的 Excel 测算结果。这并不意味着大模型可以取代专业的财务判断,但在指令明确、数据条件充分的前提下,前沿大模型已能够高质量完成标准化分析任务。这也呼应了 GDPval 所关注的方向:在高度数字化的职业场景中,大模型正逐步展现出可落地的实务可行性,并在效率与成本上具备优势。
业界关注度高的5个大模型评测数据集
1. CUFEInse | 中央财经大学保险学院、中国精算研究院 | 2025-08
保险领域的大模型评测基准,通过14,430 道多题型任务,系统评估模型在保险专业知识、行业理解、安全合规、智能体应用与推理严谨性等方面的能力。
2. 库帕思金融大模型评测数据集 | 库帕思科技| 2024-12
面向金融领域的大模型评测基准,围绕金融安全、风险控制、业务辅助与专业认知等核心场景,构建大规模、多维度的评测任务,用于系统评估模型在真实金融应用中的综合能力。
3. AI-Ceping 大模型测评知识库 | 同济大学 | 2024-07
面向大模型评测与微调的知识库数据集,汇集社区共建的高质量 AI 语料,覆盖多样化评测与训练场景,支持模型能力验证与持续优化。
4. CS-Eval 大模型网络安全评测数据集 | 阿里安全、复旦大学和中国科学院大学 | 2024-06
网络安全领域的大模型评测基准,覆盖多个安全子领域与题型,结合知识型与实战型任务,用于全面评估模型的网络安全理解与分析能力。
5. OmniMedVQA 大规模医学 VQA 评测数据集 | 香港大学、上海人工智能实验室 | 2024-03
面向医学多模态大模型的视觉问答评测基准,涵盖多器官、多模态医学影像与问答任务,用于系统评估模型的医学视觉理解与推理能力。



_1769672084863.jpg)