

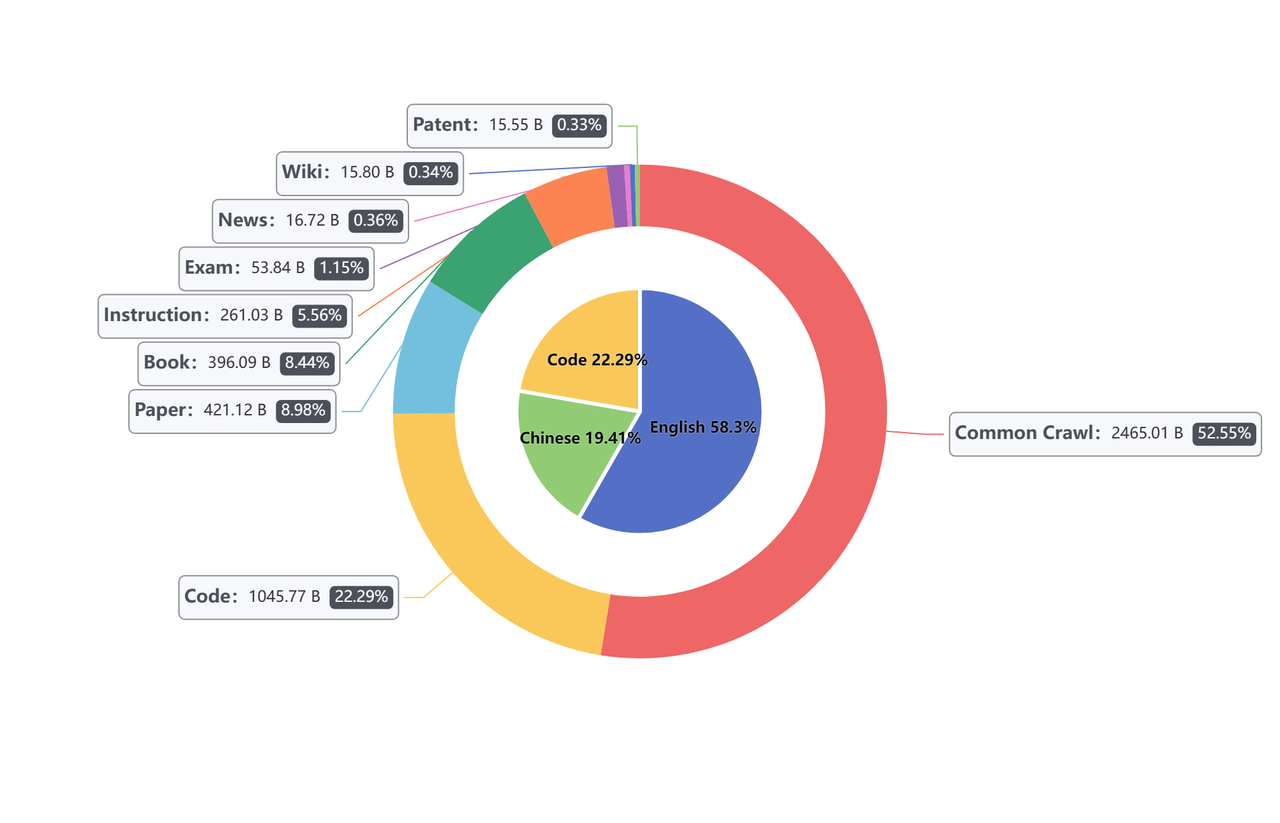
Matrix是M-A-P(Multimodal Art Projection)发布的一个大规模开源双语(英文和中文)预训练数据集。该数据集用于训练neo大模型,包含了46900亿个Token。Matrix数据集由多个元素构成,每个元素都来自不同的来源,并在语言建模和处理中发挥着不同的作用,以下是各个元素的简要介绍:
-
Common Crawl:汇聚互联网文本,涵盖网站、博客、新闻等,体现语言多样性。
-
代码:集成编程相关数据,丰富模型对技术语言的理解。
-
论文:融合多学科学术论文,提供专业和技术性语言素材。
-
书籍:涵盖文学、非虚构、教材等,拓宽语言模型的知识面。
-
指令:以问答形式呈现,增强模型对指令性语言的识别。
-
考试:整合学术考试材料,提升模型对教育性文本的处理能力。
-
新闻:集合新闻报道,使模型紧跟时事动态。
-
维基:不仅限于维基百科,包括百科全书类文章,覆盖广泛领域。
-
专利:纳入专利文献,为模型提供详尽的发明描述。
详情请参见五号雷达:https://www.5radar.com/result?key=Matrix



_1769672084863.jpg)