

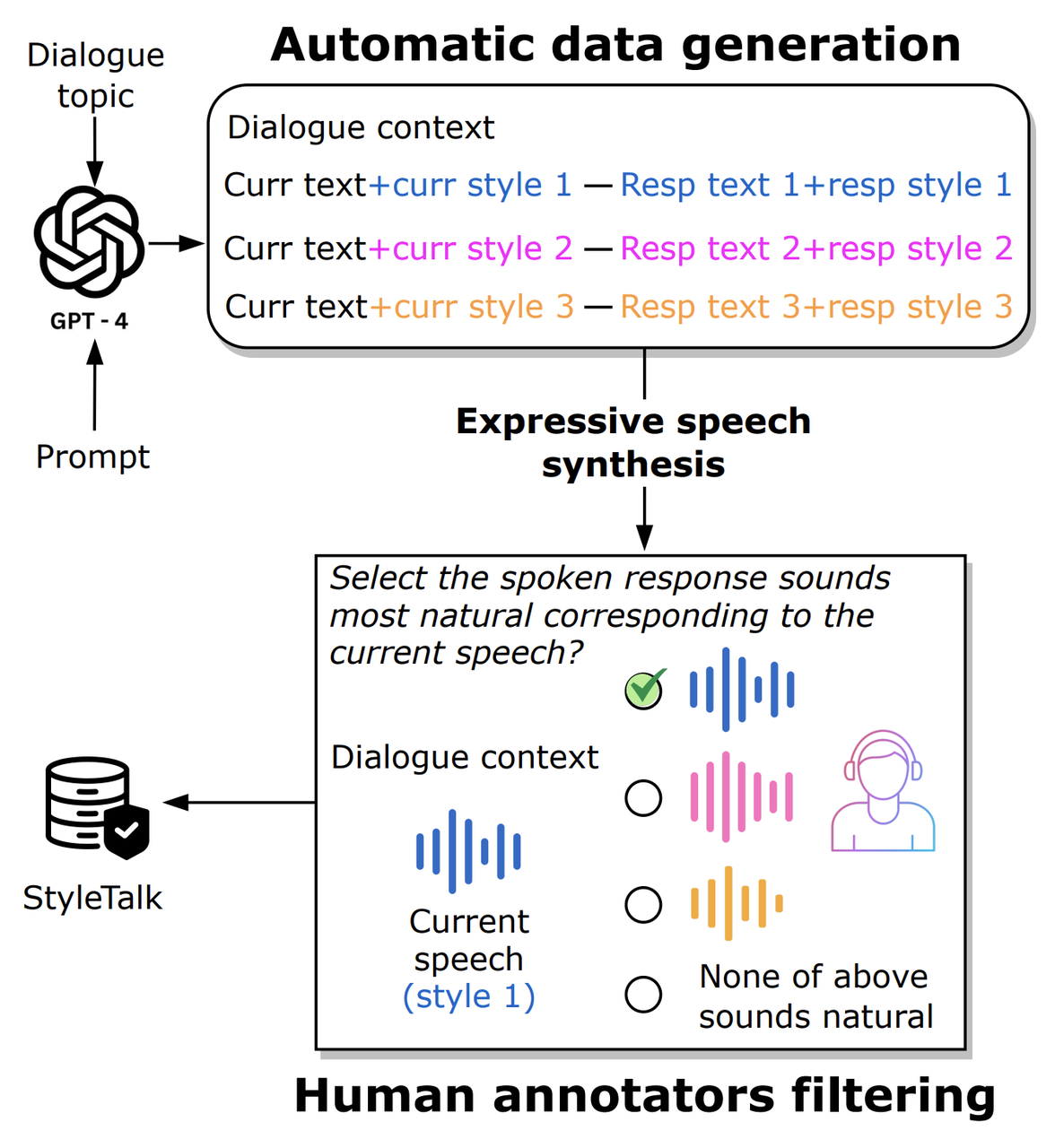
StyleTalk数据集由台湾大学构建,它是为了帮助大模型更好地理解和回应不同说话风格而创建。该数据集的训练集包含1,878组对话和1,986个样本,评估集包含486组对话和981个样本,其是首个具有相同对话背景和输入句子但不同说话风格的口语对话基准数据集,并且每种风格都配有相应的表达性口语回应。数据集的创建过程分为三个阶段:首先利用大模型生成带有风格标注的文本对话;其次,通过表达性文本到语音模型合成具有特定风格和韵律控制的语音;最后,通过人工审核确保数据的自然性和质量。StyleTalk数据集旨在促进开发理解并响应不同言语风格的对话系统以及提高大模型对语音模态的理解和响应能力,以增强用户体验。
详情请参见五号雷达:https://www.5radar.com/result?key=StyleTalk



_1769672084863.jpg)