

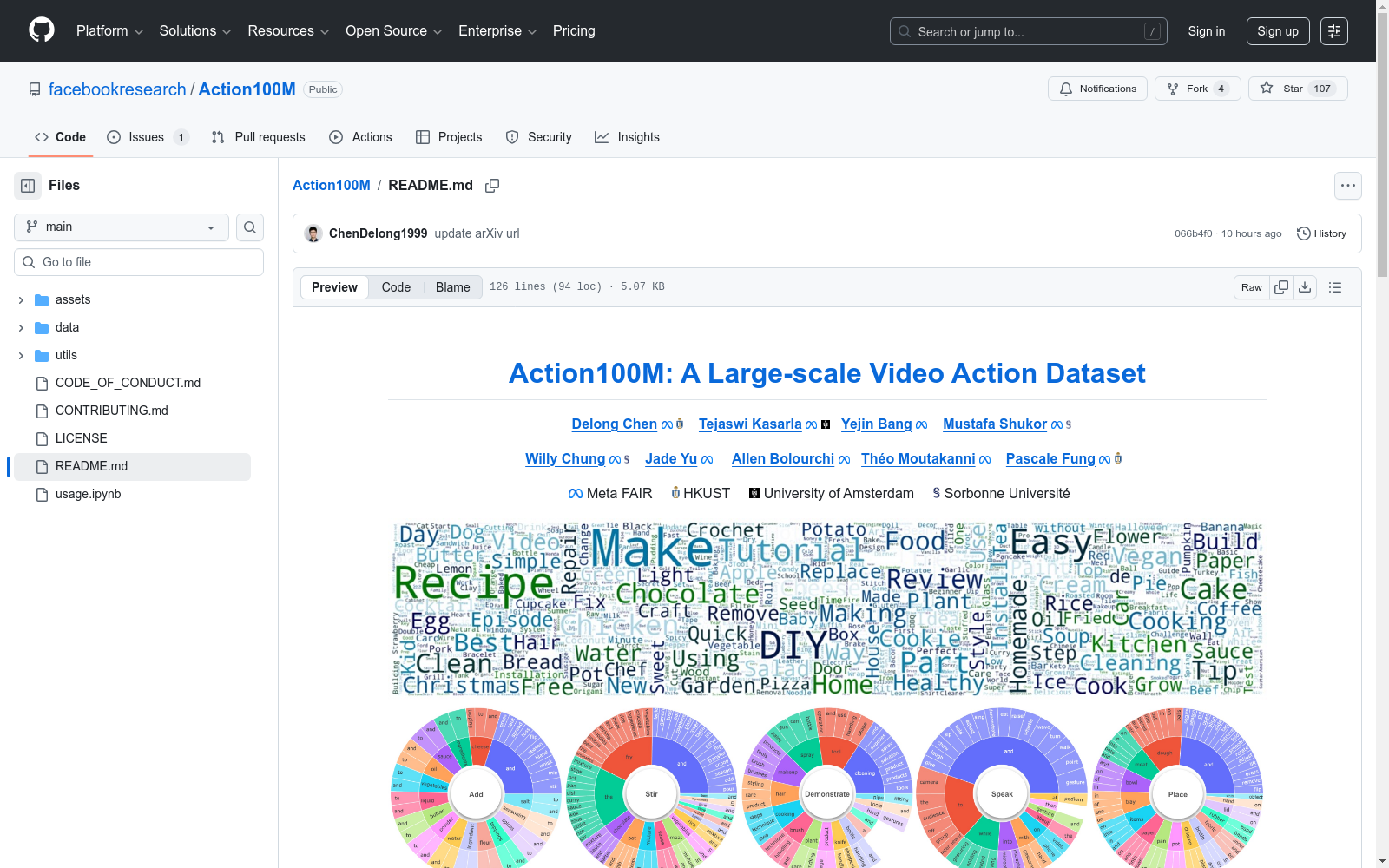
Meta FAIR本次发布的数据集Action100M,Action100M是由Meta FAIR等机构联合构建的大规模视频动作数据集,包含来自120万条互联网教学视频的1.47亿个时序标注片段,总时长相当于14.6年。数据集通过自动化流水线生成,采用V-JEPA 2嵌入进行分层时序分割,并组织为树状多级字幕结构,最终通过GPT-OSS-120B推理模型输出结构化标注。其21.3亿单词量的丰富标注支持开放词汇动作识别,在VL-JEPA模型训练中展现出卓越的零样本性能,为视频理解与物理世界建模研究提供了新基准。
README内容:
关于Meta FAIR,Meta FAIR(Fundamental AI Research)是Meta公司旗下的人工智能研究实验室,致力于推动人工智能领域的基础研究,涵盖机器学习、计算机视觉、自然语言处理等多个方向。
关于arXiv,arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)