

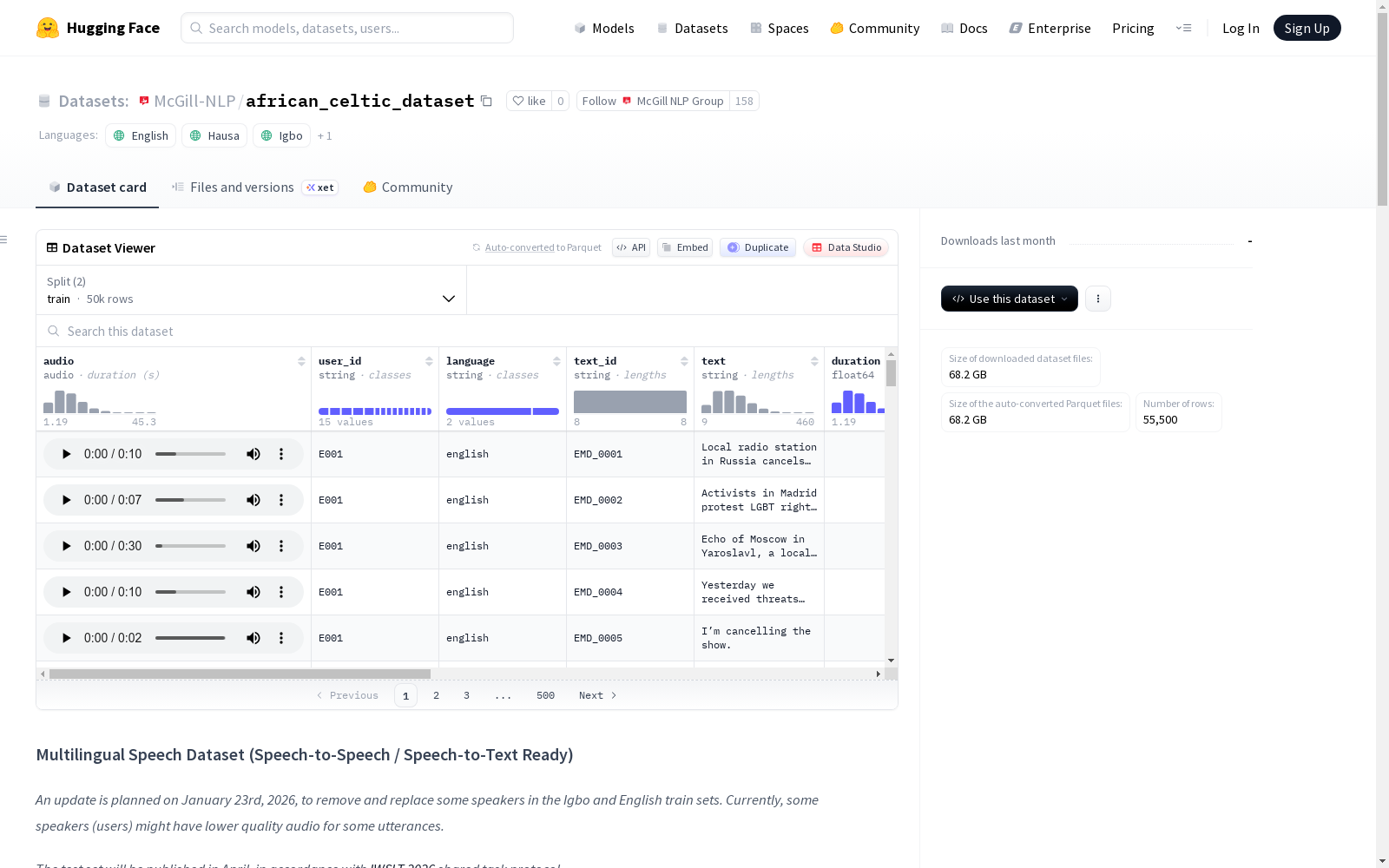
McGill NLP Group本次发布的数据集african_celtic_dataset,该数据集是一个大规模的多语言语音语料库,专为语音到语音翻译、语音到文本以及多语言语音处理研究而设计。数据按语言、说话者(`user_id`)和数据集分割(`train`、`dev`)组织,并包含丰富的声学和元数据注释。数据集目前包括约鲁巴语(`Y`)、伊博语(`I`)、豪萨语(`H`)和英语(`E`)的语音数据。每个样本包含音频波形、说话者标识符、语言、文本转录、音频时长、录音时间戳、原始采样率、静音比例、信噪比、语音速率、平均音量等字段。数据集主要用于语音到语音翻译、语音到文本、多语言和低资源语音建模、声学分析和语音质量研究等用途,但不适用于说话者识别或验证、监视或生物特征分析等场景。
Dataset card内容:
Files and versions内容:
关于McGill NLP Group,麦吉尔自然语言处理小组(McGill-NLP)是专注于计算语言学和自然语言处理研究的学术团队。
关于HuggingFace,Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)