

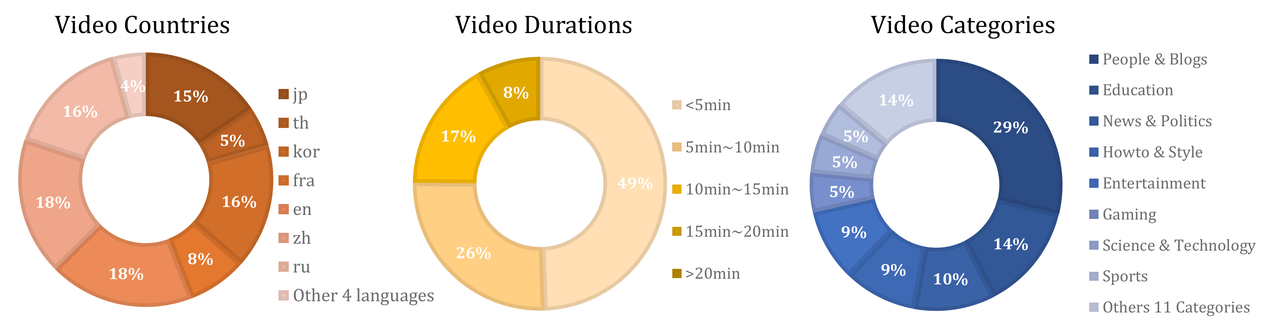
上海人工智能实验室联合南京大学、中国科学院等机构联合发布高质量大规模视频-文本数据集InternVid,旨在应对日益扩大的视频-语言建模规模需求,推动大模型视频理解和生成能力进一步提升。作为当前全球最大的视频-文本公开数据集之一,InternVid包含超700万条配有详细文本描述的视频,涵盖16种场景和约6000个动作描述,总时长接近76万小时,并具备高视频-文本对应性,数据集中的视频与文本描述高度匹配,为视频-文本语义匹配、视频-文本检索、视频-文本生成等多模态学习任务训练提供“视频词典”。InternVid受到学术界广泛关注,已应用于多模态世界模型LWM,并被Google、Stable AI的视频生成工作使用或参考,相关论文在2024年国际表征学习大会(ICLR 2024)获Spotlight。
详情请参见五号雷达:https://www.5radar.com/dataset?id=870057b76047b507144b03ffa6d7524b



_1769672084863.jpg)