

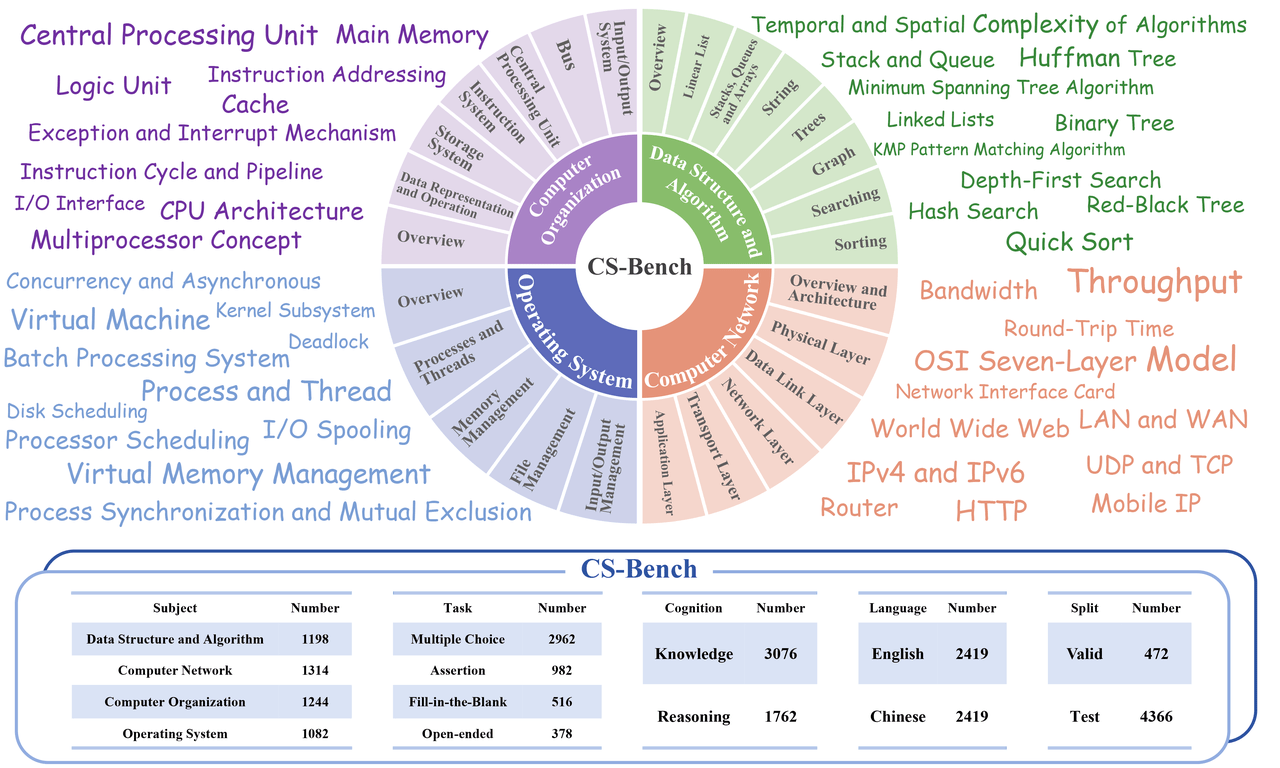
CS-Bench由北京邮电大学构建,是首个致力于评估大型语言模型(LLMs)在计算机科学领域表现的双语(中英)基准测试数据集。该数据集包含约5000个精心策划的测试样本,覆盖计算机科学的4个主要领域及26个子领域,包含多种任务形式和知识推理类型。数据集的内容涵盖了计算机科学领域的广泛主题,包括但不限于编程语言、算法、数据结构等。通过CS-Bench,研究人员对30多个主流大型语言模型进行了全面评估,揭示了模型规模与计算机科学表现之间的关系,并定量分析了现有模型的失败原因,指出了改进方向,包括知识补充和特定于计算机科学的推理能力。
详情请参见五号雷达:https://www.5radar.com/dataset?id=88126ae4e0bb65fd6ca18e16f82dcc4f



_1769672084863.jpg)