

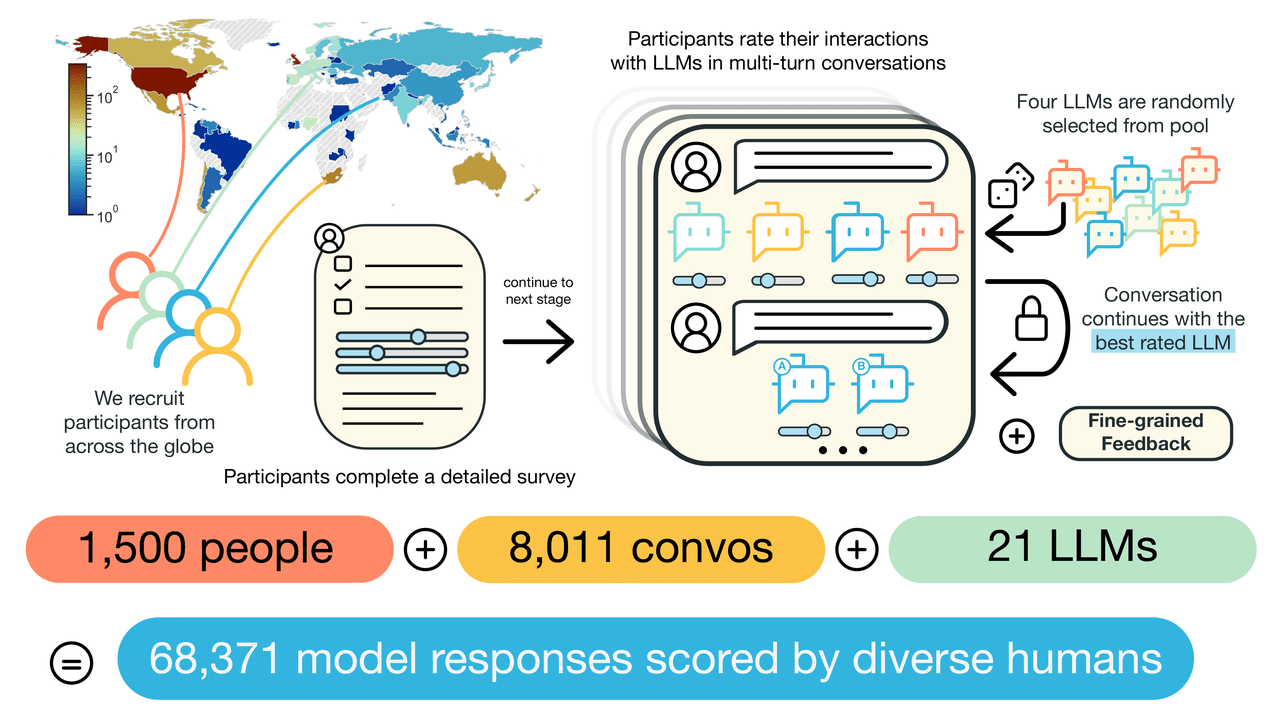
PRISM数据集由牛津大学、宾夕法尼亚大学、MeatAI等机构联合构建,是一个开创性的多语言反馈数据集,旨在深入探索和理解大型语言模型(LLMs)的主观和多元文化对齐问题。该数据集包含了来自75个国家的1500名不同参与者的背景信息、偏好声明,以及他们在与21个LLMs进行的8011次实时对话的反馈。PRISM数据集以其广泛的地理和人口统计参与度,为AI发展中的人类反馈数据提供了新的视角,它不仅包含两个具有代表性的样本(英国和美国),以理解集体福祉,还通过将每个评分链接到详细的参与者档案,允许研究个性化和样本偏差。此外,PRISM强调了在价值负载和有争议的话题上的对话多样性、偏好多样性以及福利结果,展示了人类在设定对齐规范时的重要性。该数据集旨在通过这些详细的数据,探索和理解人们对于AI语言模型行为的偏好和期望,以及如何在设计和开发中实现更广泛的参与和代表性。
详情请参见五号雷达:https://www.5radar.com/dataset?id=9a484cfff8d58050d58514cc4a081530



_1769672084863.jpg)