

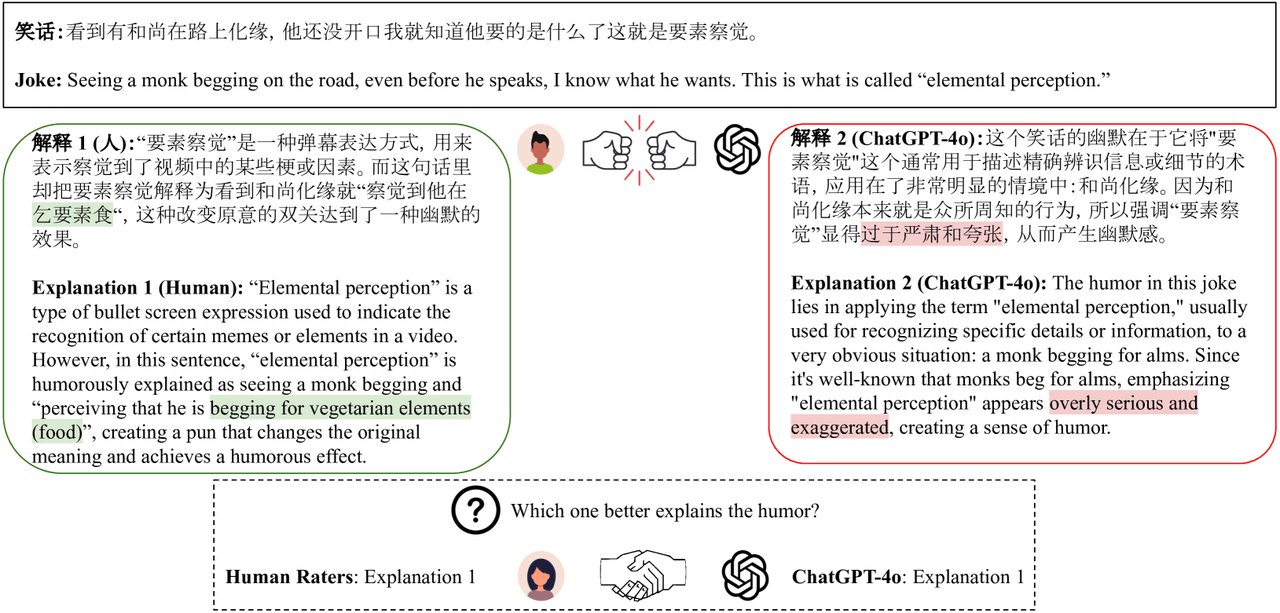
Chumor 1.0由密歇根大学、卡内基梅隆大学和上海交通大学联合构建,是一个专注于中文幽默理解的数据集。该数据集从中国版Reddit平台“弱智吧”(RZB)收集而来,包含2018至2021年间的年度最佳帖子和版主推荐内容。Chumor的特点是,它不仅包含了笑话本身,还为每个笑话提供了手动注释的解释,这有助于深入理解笑话背后的文化和智力因素。Chumor 1.0拥有1951个笑话的注释,平均每则笑话的解释长度为78个中文字符,总字符数达到151,730,堪比一部中篇小说的规模。Chumor数据集对现有的最先进大型语言模型(LLMs)提出了挑战,实验评估表明,即使是最先进的LLMs在解释Chumor中的笑话时也存在困难,而人类提供的解释在质量上明显优于机器生成的解释。该数据集的发布,为研究者提供了一个挑战性的中文幽默理解资源,有助于推动多语言LLMs的发展和文化理解能力的增强。
详情请参见五号雷达:https://www.5radar.com/dataset?id=8a3821a7c7b2c53ea4a0b3011a445519



_1769672084863.jpg)