

2 月 6 日,腾讯混元携手复旦大学推出 CL-Bench 数据集 —— 聚焦大模型上下文新知识学习与复杂任务处理的真实场景评测基准。
大模型“会推理”,但上下文学习能力有限
虽然当前大语言模型在问答、推理、总结方面表现不错,但一到真实业务场景,短板就开始显现:
- 1. 过度依赖预训练知识:遇到新领域、新规则、新流程时容易失效。
- 2. 泛化能力不足:在更复杂、强上下文依赖的任务中,模型能成功解决的任务比例明显下降。
针对上述问题,研究团队从评测入手推出 CL-Bench,用更具挑战性的真实任务,检验模型是否真正“学得会”,而不是只依赖记忆。
CL-Bench 的核心设计
- 1. 真实复杂任务构建:包含 500 个复杂上下文、1,899 个任务、31,607 条验证规则的评测集,全部由领域专家设计,覆盖多种专业与业务场景。
- 2. 强上下文依赖机制:每道题所需知识仅存在于当前上下文中,预训练阶段未曾见过,模型必须现场学习而非记忆调用。
- 3. 能力导向评测方式:不再测试简单检索或阅读理解,强调“读懂 → 学会 → 应用”的完整学习闭环。
- 4. 贴近真实应用:任务形态模拟现实工作流、规则系统与专业决策过程,更贴合企业与科研实际使用场景。
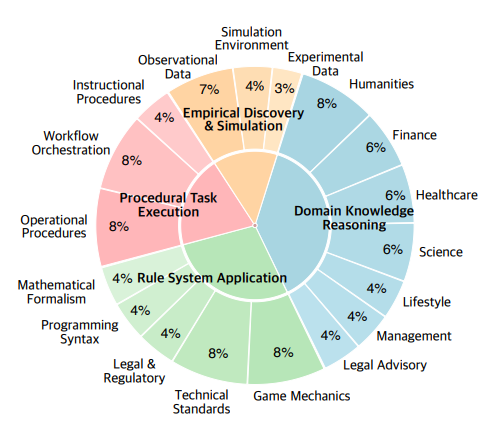
在此基础上,CL-Bench 将真实世界中的上下文学习场景系统划分为四大能力类别。
四大类别概览
- 1. 领域知识推理:提供金融、医疗、法律、人文等专业知识背景,模型需学习新领域知识后完成分析、裁决与咨询等任务。
- 2. 规则系统应用:提供新规则体系(如游戏机制、法规标准),模型需理解规则并正确推理、执行。
- 3. 程序化任务执行:提供操作手册、软件文档或流程说明,模型需按步骤完成故障排查、操作指导和工作流调度。
- 4. 经验发现与仿真:提供实验数据、观测记录或模拟环境,模型需从数据中归纳规律并进行推理决策。
基于上述四类任务,研究团队对多款主流大模型进行了系统评测。
模型表现
- 1. 整体成功率偏低:10 个主流前沿模型平均仅完成 17.2% 的任务, 表现最好的 OpenAI GPT-5.1 也仅完成 23.7%。
- 2. 能力瓶颈明显:结果表明当前大模型仍难以实现有效的上下文学习,距离真实复杂场景应用仍存在显著差距。
数据集地址: CL-Bench
论文地址: CL-bench: A Benchmark for Context Learning



_1769672084863.jpg)