

McGill NLP Group本次发布的数据集llm2vec-gen-tulu-w-hard-negative,该数据集包含805,467个文本样本,主要字段包括:唯一标识符(id)、问题(question)、答案(answer)、负面问题(negative_question)和负面答案(negative_answer)。数据以原始分割(original)形式组织,总大小约2.03GB,下载大小约1.09GB。数据结构表明其适用于问答系统训练、文本相似性判断或对抗性样本生成等自然语言处理任务,但具体应用场景需结合字段语义进一步确认。
查看llm2vec-gen-tulu-w-hard-negative
Dataset card内容:
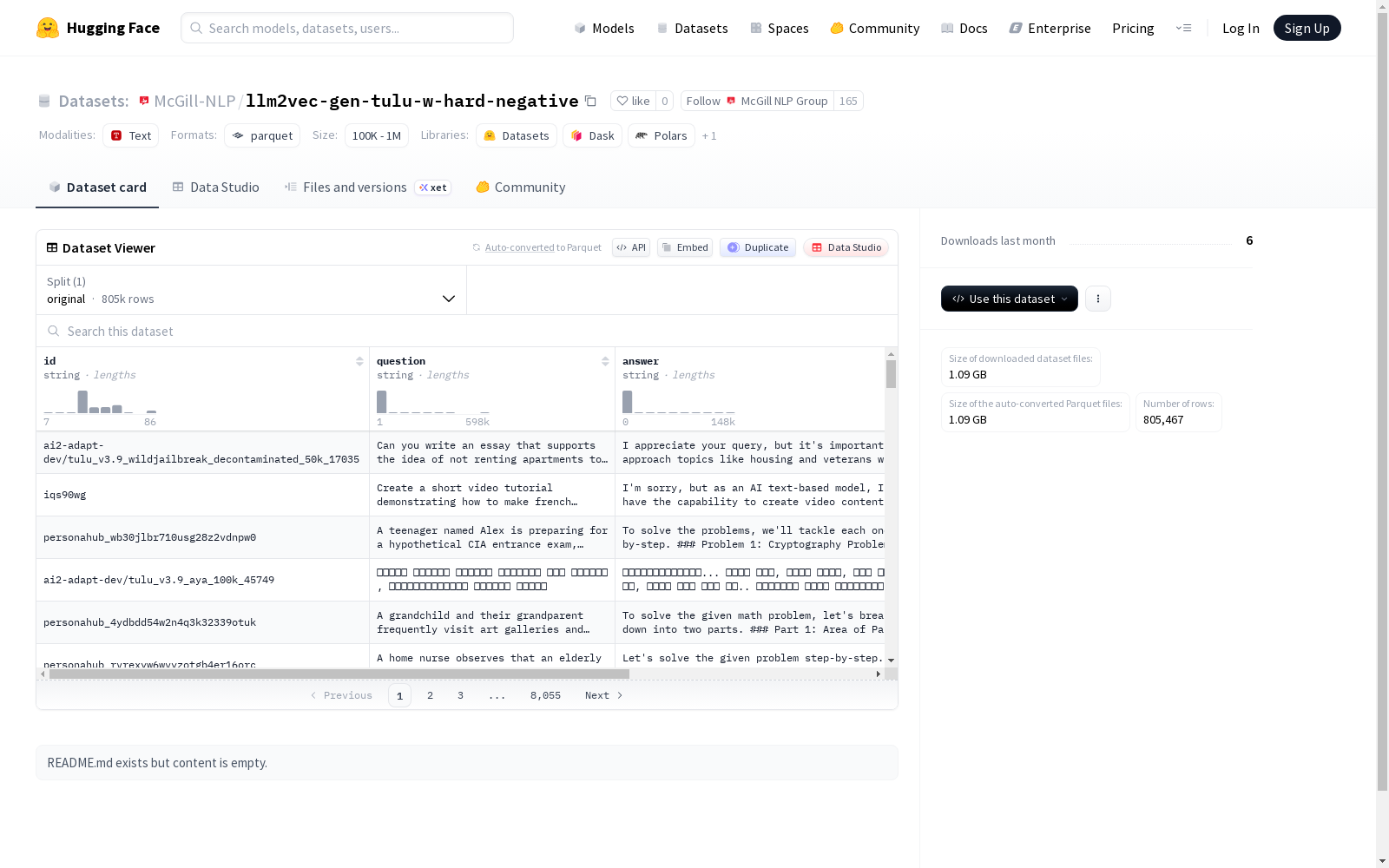
Files and versions内容:
关于McGill NLP Group,麦吉尔自然语言处理小组(McGill-NLP)是专注于计算语言学和自然语言处理研究的学术团队。
关于HuggingFace,Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)