

McGill NLP Group本次发布的数据集llm2vec-gen-tulu,LLM2Vec-Gen数据集基于Tulu-3 SFT数据生成,旨在为训练LLM2Vec-Gen模型提供目标输出响应。数据集包含多个分片,每个分片对应由不同大型语言模型(如Qwen3-4B、Llama_32_1B_Instruct等)生成的响应。原始Tulu-3响应保存在original分片中。每个数据实例包含三个字段:id(原始ID)、question(原始查询)和answer(由特定模型生成的文本)。数据集总规模为21,105,463,124字节,包含806,413个示例,适用于自然语言生成任务和模型训练。
Dataset card内容:
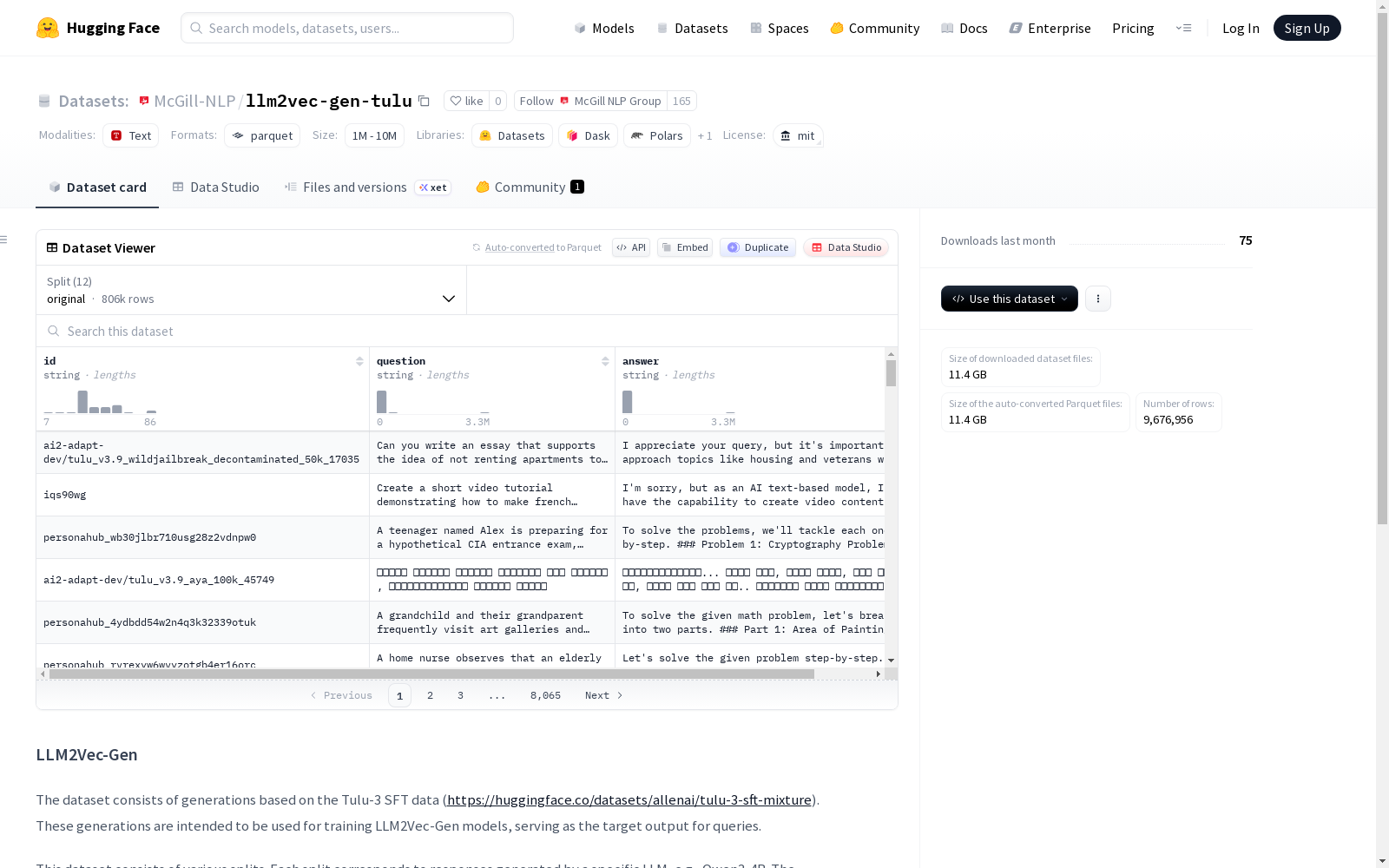
Files and versions内容:
关于McGill NLP Group,麦吉尔自然语言处理小组(McGill-NLP)是专注于计算语言学和自然语言处理研究的学术团队。
关于HuggingFace,Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)