

NVIDIA本次发布的数据集Nemotron-Terminal-Corpus,Terminal-Corpus 是一个大规模监督微调(SFT)数据集,专为提升大型语言模型(LLM)的终端交互能力而设计。该数据集由 NVIDIA 开发,采用 Terminal-Task-Gen 流程构建,结合了数据集适配和跨多个领域的合成任务生成。数据集包含约 366,000 条高质量执行轨迹,分为两大类别:数据集适配器(约 226,000 样本),将高质量的数学、代码和软件工程数据集转换为基于终端的格式;以及基于技能的合成任务(约 140,000 样本),从结构化终端技能分类中生成的新任务。实验结果表明,使用该数据集训练的模型在 Terminal-Bench 2.0 基准测试中表现优异,显著优于基础模型,并在复杂领域实现了功能性的突破。数据集适用于问答任务,主要语言为英语,采用 cc-by-4.0 许可。
Dataset card内容:
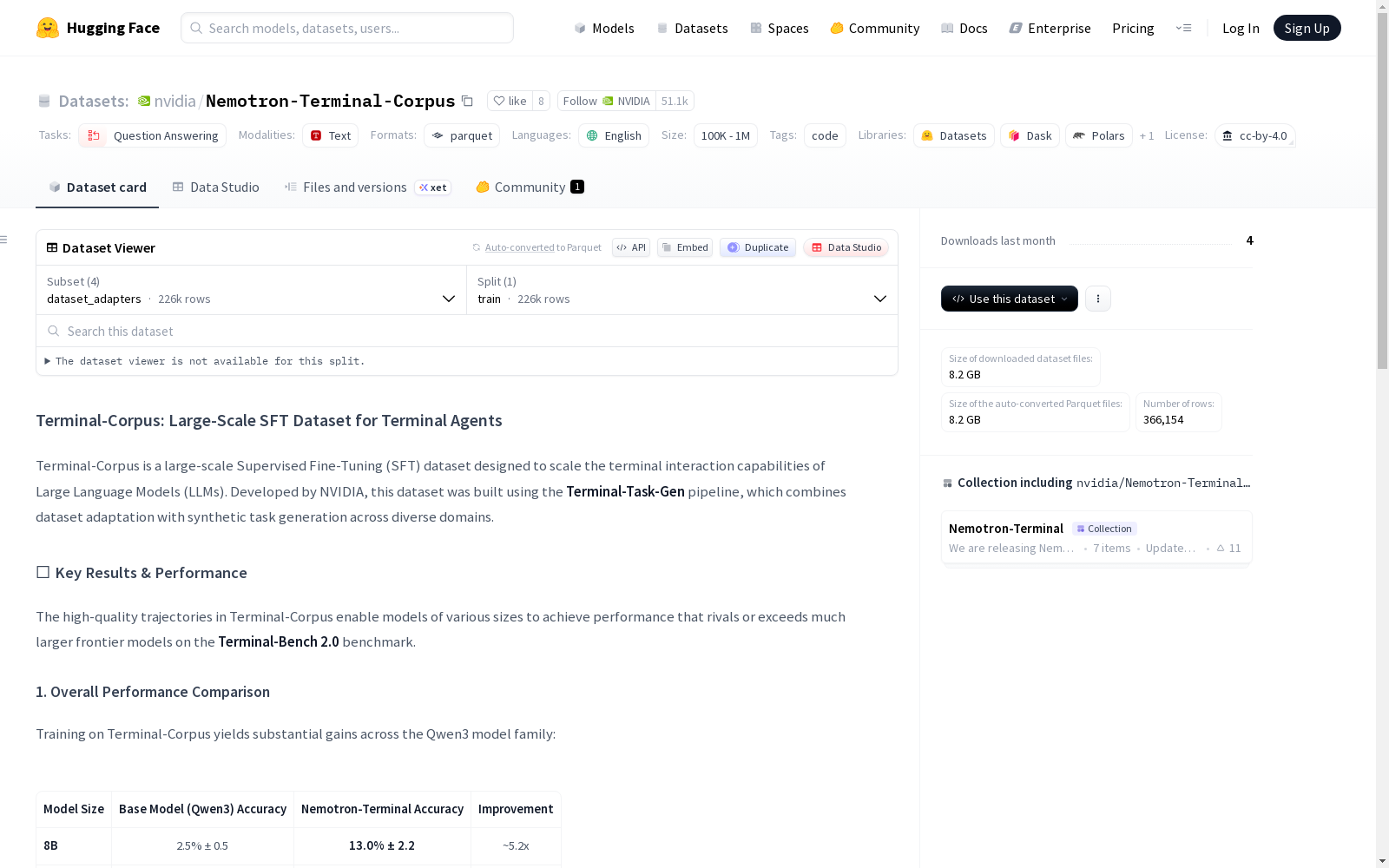
Files and versions内容:
关于NVIDIA,英伟达是一家专注于图形处理器开发的全球知名技术公司。
关于HuggingFace,Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)