

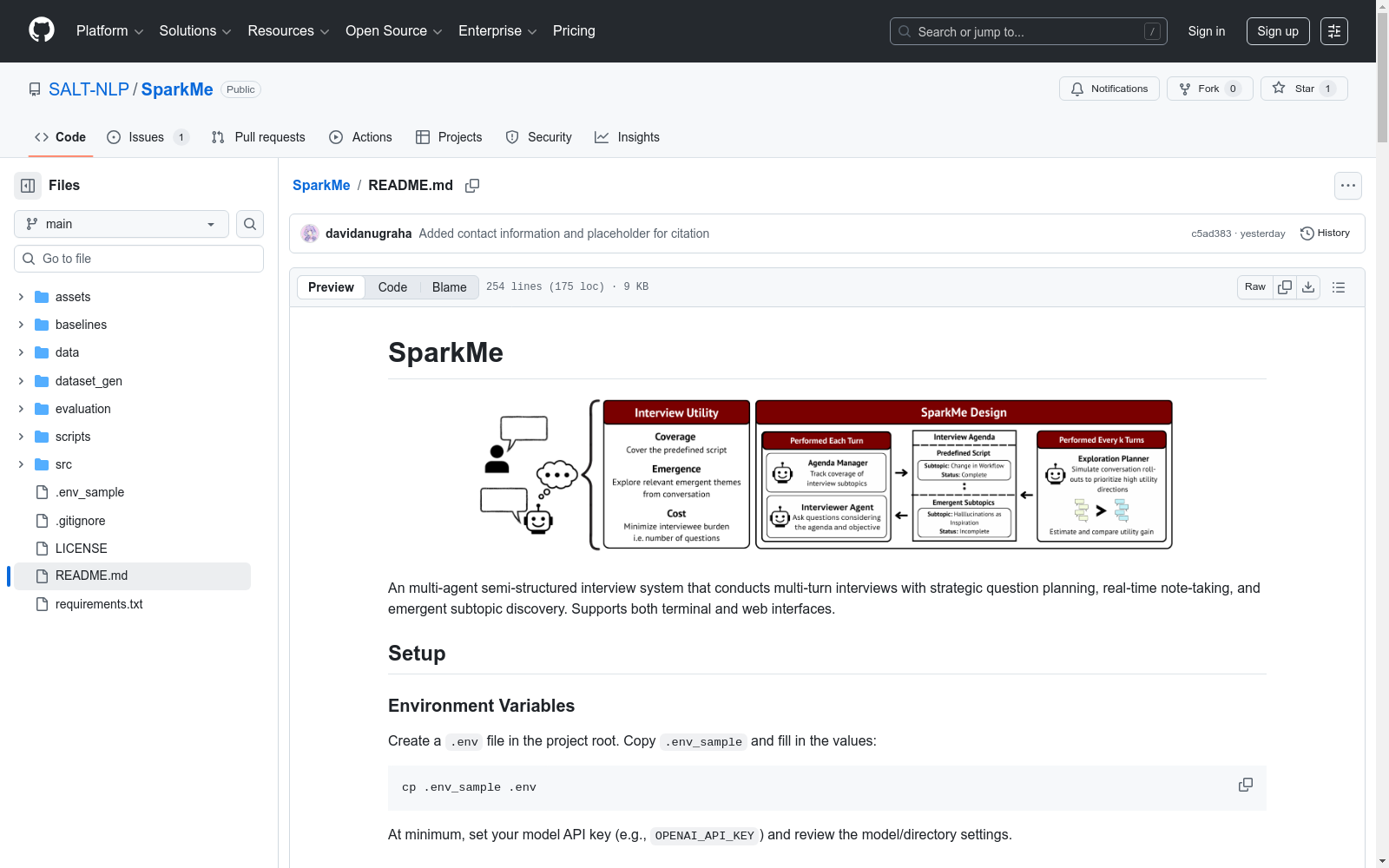
斯坦福大学本次发布的数据集SparkMe,SparkMe数据集由斯坦福大学研究团队创建,旨在支持基于大型语言模型的半结构化访谈自动化研究。该数据集包含多职业参与者的访谈记录,覆盖7个不同领域的70名受访者数据,通过模拟对话和真实用户研究生成。数据来源包括人工设计的访谈主题指南和动态涌现的对话子话题,采用多智能体架构进行系统性采集与标注。该数据集主要用于优化访谈算法的覆盖率和探索性,解决传统定性研究中专家访谈规模受限的问题,可应用于政策制定、产品设计等需要深度定性洞察的领域。
README内容:
关于斯坦福大学,斯坦福大学是一所位于美国加州的世界顶尖私立研究型大学,以其在科技、工程、商业和法律等领域的卓越教学和研究而闻名。
关于arXiv,arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)