

LAION eV本次发布的数据集Sera-4.5A-Full-T1-v2-1000,该数据集包含1000个训练样本,每个样本由对话内容(包含角色和内容字段)、来源和实例ID组成。数据集以结构化格式存储,总大小为151374656字节。数据具体用途和背景未在README中明确说明,但结构表明其可能用于对话系统或自然语言处理相关任务。
Dataset card内容:
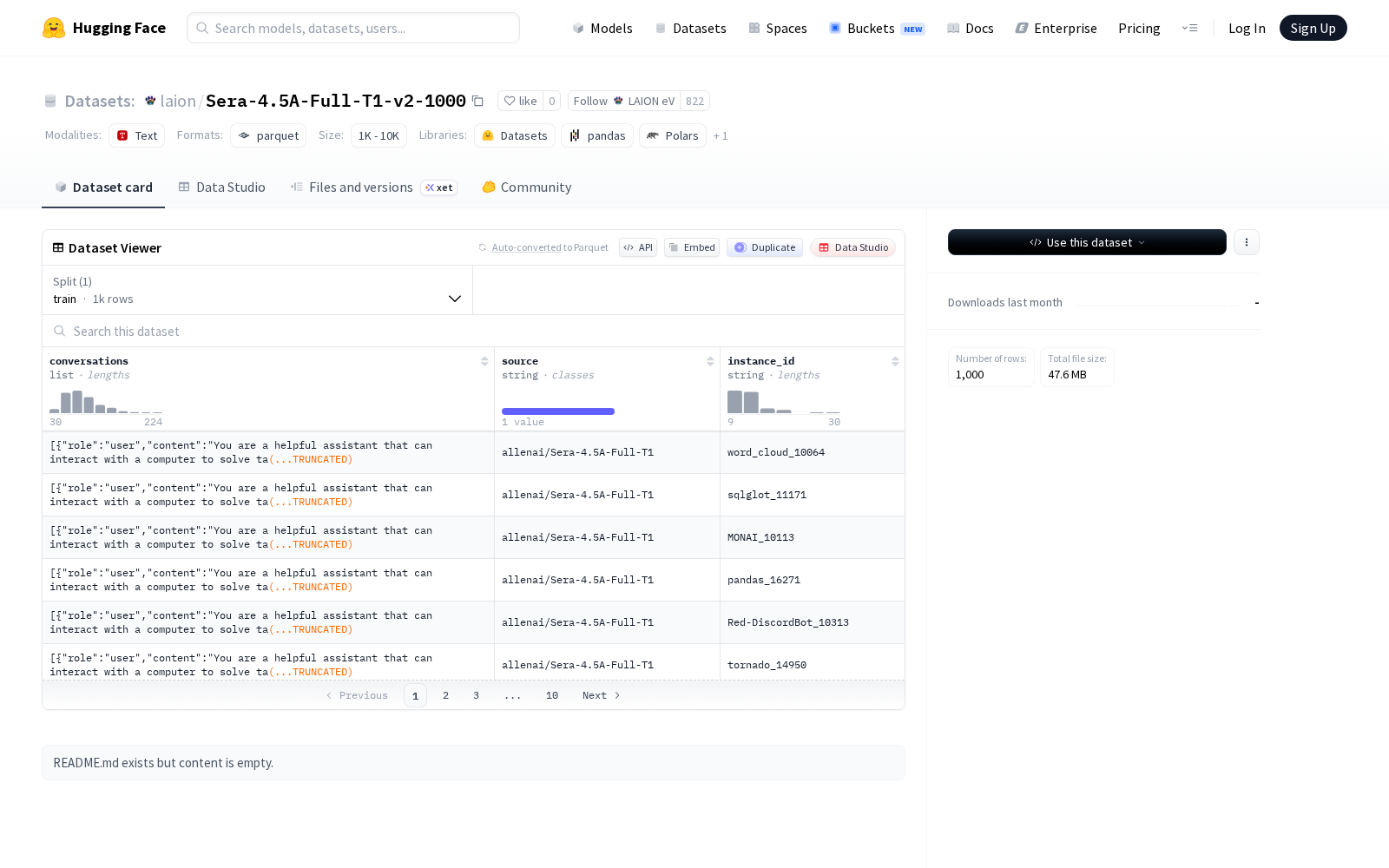
Files and versions内容:
关于LAION eV,LAION是一个专注于构建大规模图像-文本对数据集的开源项目。
关于HuggingFace,Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的开发与分享。它提供了丰富的资源,包括超过100万个模型、25万个数据集和40万个应用程序,支持文本、图像、视频、音频和3D等多种模态。此外,平台还提供企业级解决方案和开源工具,如Transformers、Diffusers等,以加速机器学习的研究和应用。



_1769672084863.jpg)