

随着自然语言处理(NLP)技术在法律领域的落地加速,垂直场景标注数据集的供给缺口正在成为制约小语种法律智能化发展的核心瓶颈。法律文本具有极强的严谨性要求,哪怕是细微的语法错误都可能引发语义歧义,进而影响司法判决、行政指令、商事合同的法律效力与执行效率,而罗马尼亚语作为中东欧地区代表性的小语种,长期以来缺乏面向法律垂直领域的专业语法纠错标注数据集,相关模型训练始终面临低资源场景的约束。
近日,布加勒斯特理工大学研究团队正式在arXiv平台首发RoLegalGEC数据集,这是全球首个面向罗马尼亚语法律领域的语法错误检测与修正(GEC)专用数据集。据介绍,RoLegalGEC共包含35万条法律文本段落及其对应的错误标注,覆盖罗马尼亚语法律条文、司法文书、行政公告、商事合同等多类法律与行政文件。为了最大程度贴近真实应用场景,研究团队采用合成生成方法构建数据集,通过语法规则逆向应用、场景化噪声注入、大语言模型定向提示等多种技术组合,模拟真实法律文档撰写过程中可能出现的各类语法错误,避免了人工标注成本高、样本覆盖不全的问题。
该数据集的核心定位是支撑罗马尼亚语低资源场景下的语法纠错模型训练,解决法律文本因语法错误导致的语义歧义问题,为法律专业辅助工具开发提供数据基础。从典型应用方向来看,基于RoLegalGEC训练的模型可落地于多类场景:一是法律公文智能校验,为法院、行政机构、律师事务所提供法律文书的自动语法纠错服务,降低人工审核成本,提升正式文书的严谨性;二是智能法律辅助工具开发,为面向公众的法律咨询AI、合同自动生成工具提供底层数据支撑,避免AI输出的法律文本出现语法误差引发的理解偏差;三是跨境法律服务场景,为涉及罗马尼亚语的跨境合规审核、合同翻译校验提供技术基础,降低企业进入中东欧市场的法务合规风险。
从数据要素行业的视角来看,垂直领域小语种标注数据集是当前全球数据要素市场的稀缺资源,RoLegalGEC的发布不仅填补了罗马尼亚语法律NLP领域的数据集空白,其采用的合成生成数据集构建路径,也为其他低资源小语种垂直领域数据集的生产提供了可复用的参考方案,对推动中东欧地区数字司法建设、小语种数字经济发展具有重要的先行意义。
Dataset card内容:
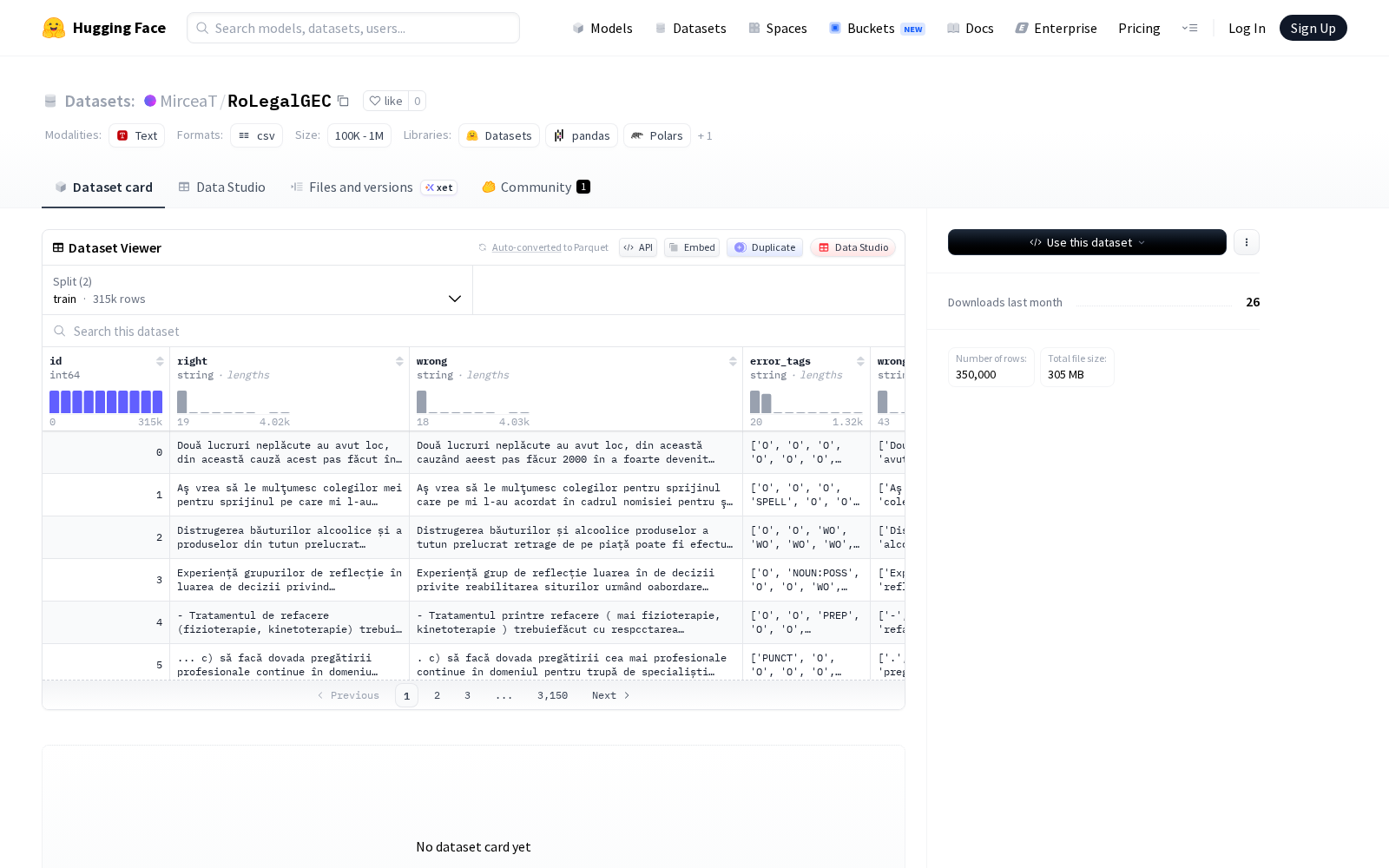
Files and versions内容:



_1769672084863.jpg)