

近年来,随着代码大模型、智能编程助手、低代码开发平台等产品的快速落地,高质量、标准化的编程类数据集已经成为AI研发领域的核心刚需资源。作为全球最大的开源AI数据集共享平台,HuggingFace已经成为全球科研机构、科技企业发布前沿AI数据集的首选渠道。2026年3月13日,深耕程序分析、AI代码生成领域研究的Northeastern University Programming Research Lab(东北大学编程研究实验室)在该平台正式首发全新mbpp-agnostic-translation数据集,为代码AI领域的研发工作再添标准化数据支撑。
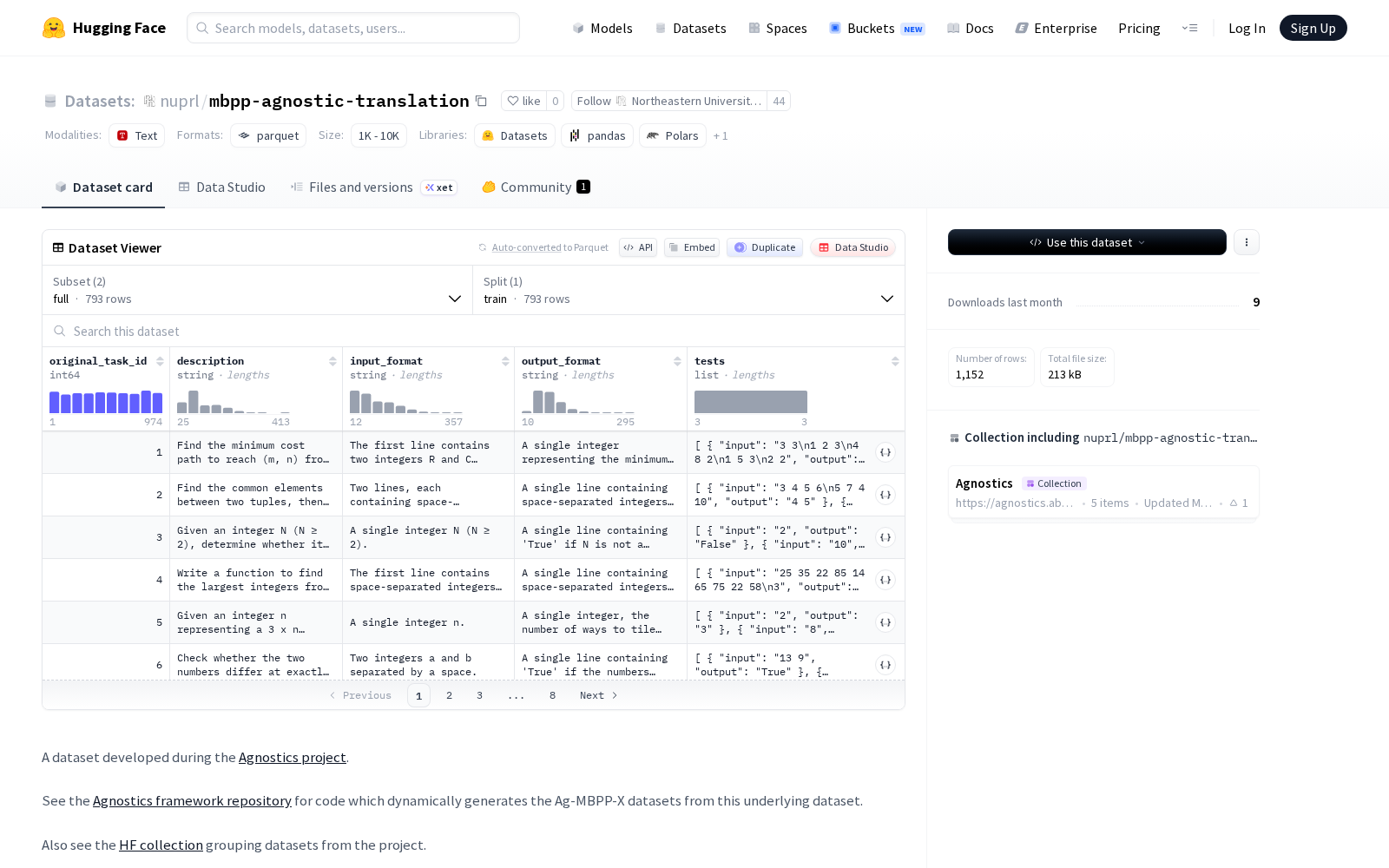
本次发布的mbpp-agnostic-translation数据集共设置两种配置供用户选择:full配置与sanitized配置,两种配置均包含统一的结构化字段:original_task_id(int64类型的任务唯一标识)、description(字符串类型的任务描述)、input_format(字符串类型的输入格式说明)、output_format(字符串类型的输出格式要求)以及tests(由输入、输出字符串组成的测试用例列表)。从样本规模来看,full配置的训练集共包含793个样本,总大小为322520字节;sanitized配置的训练集共包含359个样本,总大小为144452字节。双配置的设计也为不同需求的研发团队提供了灵活选择:full版本样本量更充足,适合需要大规模数据的模型预训练、泛化能力测试等场景;sanitized版本经过更严格的清洗筛选,数据一致性更高,适合对测试基准精度要求更高的模型效果评测、核心能力验证等场景。目前该数据集的README文档暂未明确说明其研发背景、预设目的与官方应用场景。
尽管官方未明确应用方向,但从数据集的字段设计与结构框架来看,业内普遍认为其可覆盖多个典型研发场景:一是跨编程语言的代码翻译任务训练与评测,可用于验证代码大模型将一种编程语言的逻辑迁移到另一种语言的准确率与语义一致性;二是垂直领域代码生成能力测试,标准化的输入输出格式与配套测试用例,可快速验证模型在特定开发场景下的输出合规性与逻辑正确性;三是智能编程工具的效果校验,可为IDE代码补全、低代码平台逻辑转化、自动代码纠错等产品提供标准化测试基准;四是程序语义分析相关基础研究,可支撑编程语言共性、代码逻辑等价性等方向的学术研究工作。
当前全球数据要素市场正处于快速发展阶段,垂直领域的高质量标注数据集属于高价值核心数据资产,尤其是编程类数据集,由于其对逻辑正确性、格式规范性的要求远高于通用文本数据集,研发门槛高、市场供给量相对有限。本次东北大学编程研究实验室发布的该款数据集,进一步丰富了代码AI领域的基准数据供给,有望降低相关研发团队的数据采集与清洗成本,推动行业形成更统一的代码能力评测标准,为代码大模型的工业级落地、智能编程工具的体验升级提供基础支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)