

随着AI Agent应用落地节奏加快,工具调用能力已经成为大模型适配真实场景需求的核心指标,而8B级小参数大模型凭借低算力需求、适配端侧部署的优势,正在成为消费级、轻量化AI应用的首选底座,对应细分场景的高质量微调数据集也成为行业刚需。作为全球知名的开源AI数据组织,LAION eV此前曾主导发布LAION-5B等支撑文生图技术迭代的核心开源数据集,在AI训练数据领域具备广泛的行业影响力。
本次LAION eV发布的Sera-4.6-Lite-T2-v4-316数据集,是allenai/Sera-4.6-Lite-T2数据集的精选子集,专为训练SERA-8B模型而设计。针对当前开源大模型微调环节存在的工具调用标记格式不统一、适配成本高的痛点,该数据集将OpenAI的 `tool_calls` 预渲染为Hermes/Qwen3等主流开源大模型原生支持的 `
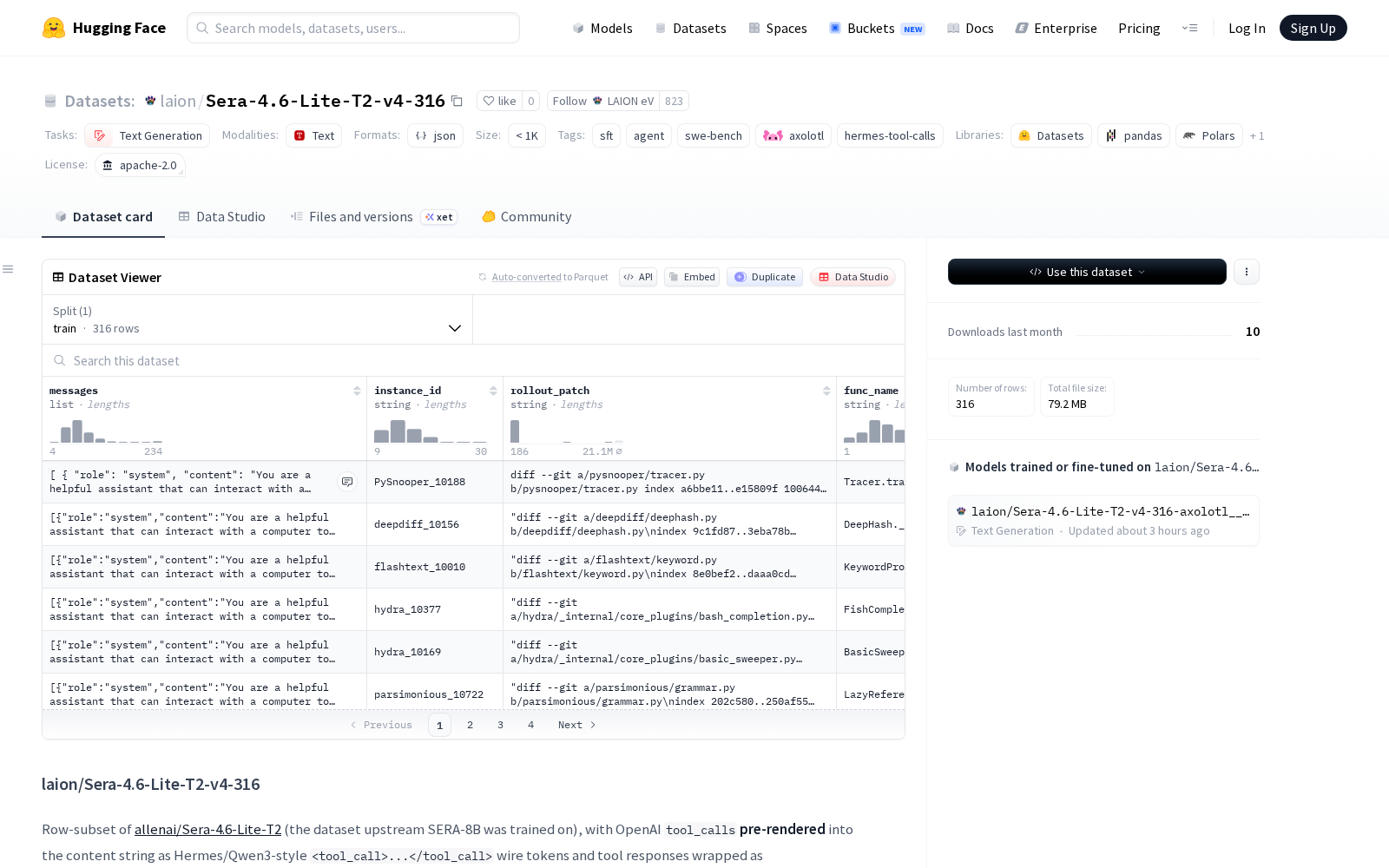
该数据集从包含36083行数据的源数据集中筛选出316行高质量标注样本,存储格式为原始JSONL,每行包含 `messages: list[role, content, train]` 字段,其中角色覆盖 `system | user | assistant` 三类对话角色,工具观察内容以 `role: user` 表示,并带有 `
从应用方向来看,该数据集既适用于通用文本生成任务的微调优化,更面向工具调用相关场景做了专项适配,典型应用方向包括轻量化端侧AI助理的智能家居控制、日程调用等工具指令训练,中小体量企业客服系统的订单查询、工单流转等API调用能力训练,以及垂直领域Agent的结构化输出、指令跟随能力增强等。相较于大规模微调数据集,该轻量化精选数据集无需高算力支撑即可完成小样本微调,普通消费级GPU即可满足训练需求,适合中小开发者、创业团队快速验证大模型工具调用能力的落地效果。
在AI训练数据作为核心生产要素的当下,该数据集的发布一方面填补了小参数大模型工具调用细分场景的高质量开源数据集空白,另一方面其采用的统一标记格式也为行业提供了可参考的工具调用标注规范,有助于降低全行业的大模型微调成本,推动轻量化AI Agent应用的普及落地。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)