

作为支撑了Stable Diffusion等多款现象级开源AI模型训练的全球领先开源数据贡献组织,LAION eV在AI训练数据集领域的技术积累一直受到全行业的广泛关注。当前代码大模型正成为AI落地企业级研发场景的核心赛道,高质量、预处理完成的代码类训练数据是制约大模型代码生成准确性、鲁棒性的核心生产要素,多数中小研发团队往往需要投入大量算力与人力完成数据清洗、分词、掩码处理等前置工作,研发门槛相对较高。
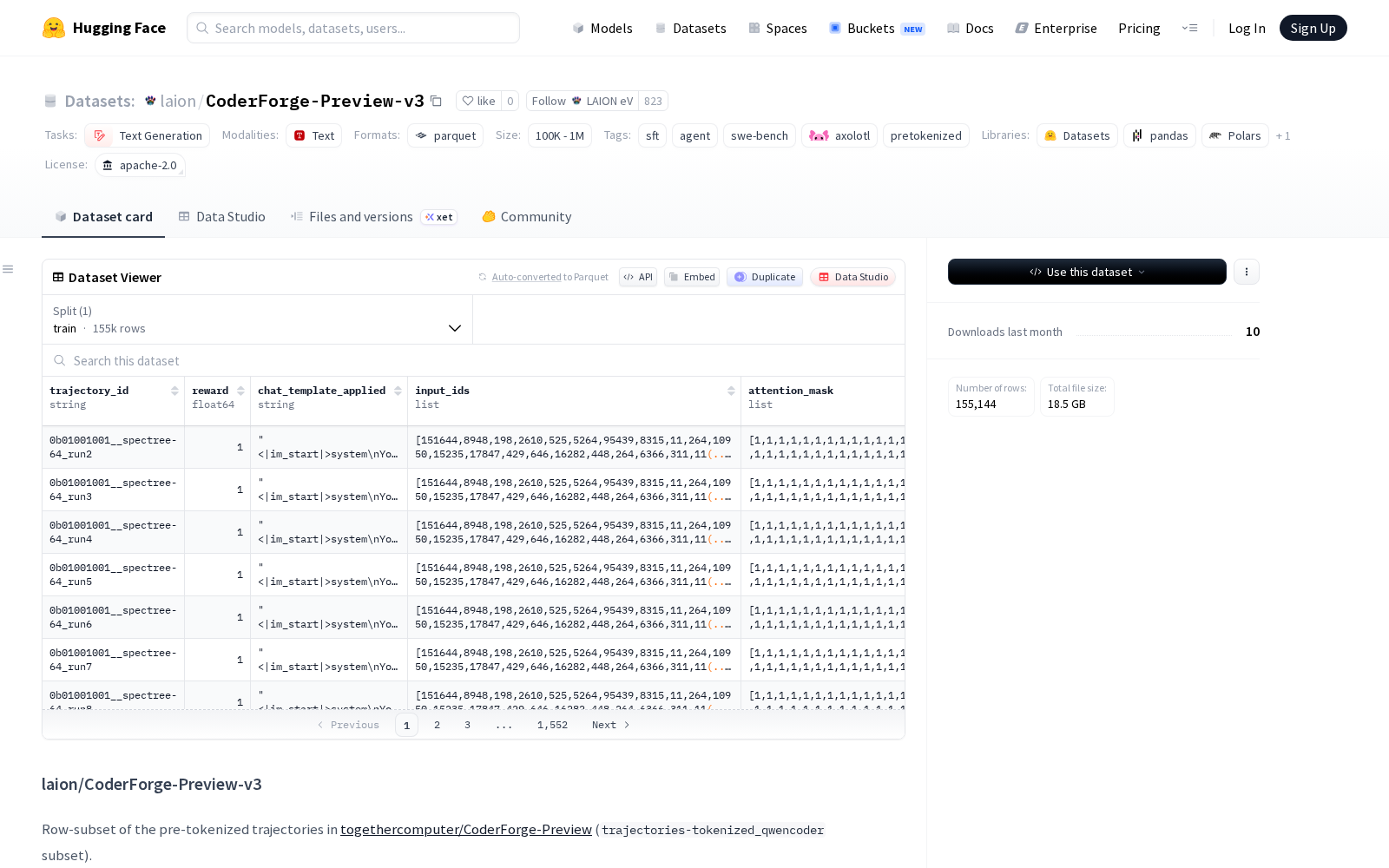
LAION eV本次发布的CoderForge-Preview-v3数据集(HuggingFace路径为laion/CoderForge-Preview-v3)是一款经过标准化预处理、预分词的专业代码类数据集,源自togethercomputer/CoderForge-Preview数据集中的trajectories-tokenized_qwencoder子集。该数据集共包含155,144行数据,来源于R2E_Gym、SWE_Rebench、SWE_Smith、filtered_reward1四大数据源,通过种子为42的确定性采样生成,数据格式为适配Qwen3系列模型的本地预分词数据(与Qwen2.5-Coder、Qwen3-Coder、Qwen3-8B共享分词器),每行包含七大字段:input_ids(int32列表)、attention_mask(int8列表,全为1)、labels(int64列表,已应用-100掩码)、chat_template_applied(调试用字符串)、trajectory_id(字符串)、reward(float64)、source(固定为togethercomputer/CoderForge-Preview/trajectories-tokenized_qwencoder)。该数据集原生适配文本生成类任务,尤其是与axolotl框架结合使用时,可直接跳过聊天模板渲染环节,大幅缩短训练流程、降低算力消耗。
从行业应用价值来看,该数据集可覆盖多个主流AI研发场景:在代码大模型产品化侧,可直接用于智能编程插件、代码缺陷自动检测、自然语言转代码(NL2Code)、多编程语言翻译等产品的模型预训练与微调,省去研发团队的繁杂预处理环节;在模型对齐阶段,自带的reward奖励字段可直接支撑奖励模型训练,适配强化学习人类反馈(RLHF)流程,优化代码大模型的输出匹配度;在学术研究侧,标准化的预分词格式也便于不同研究团队的成果复现与效果横向对比,降低NLP代码相关研究的准入门槛。本次LAION eV推出的预分词代码数据集,进一步丰富了开源AI训练数据的供给结构,对于降低大模型研发成本、推动代码AI领域的普惠化发展具有重要的行业价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)