

当前生成式AI产业进入垂直场景落地的关键阶段,代码大模型作为赋能软件研发数字化、提升开发效率的核心技术,其迭代速度高度依赖高质量标注训练数据的供给。作为全球知名的非盈利AI数据集研发机构,LAION eV曾开源LAION-5B等多个支撑生成式AI技术突破的核心公共数据集,在AI训练数据的标准化、开放化领域拥有广泛的行业影响力。2026年4月23日,LAION eV正式在HuggingFace平台上线全新预标记数据集CoderForge-Preview-v3-10000,为文本生成、代码大模型微调场景提供标准化的高质量数据供给。
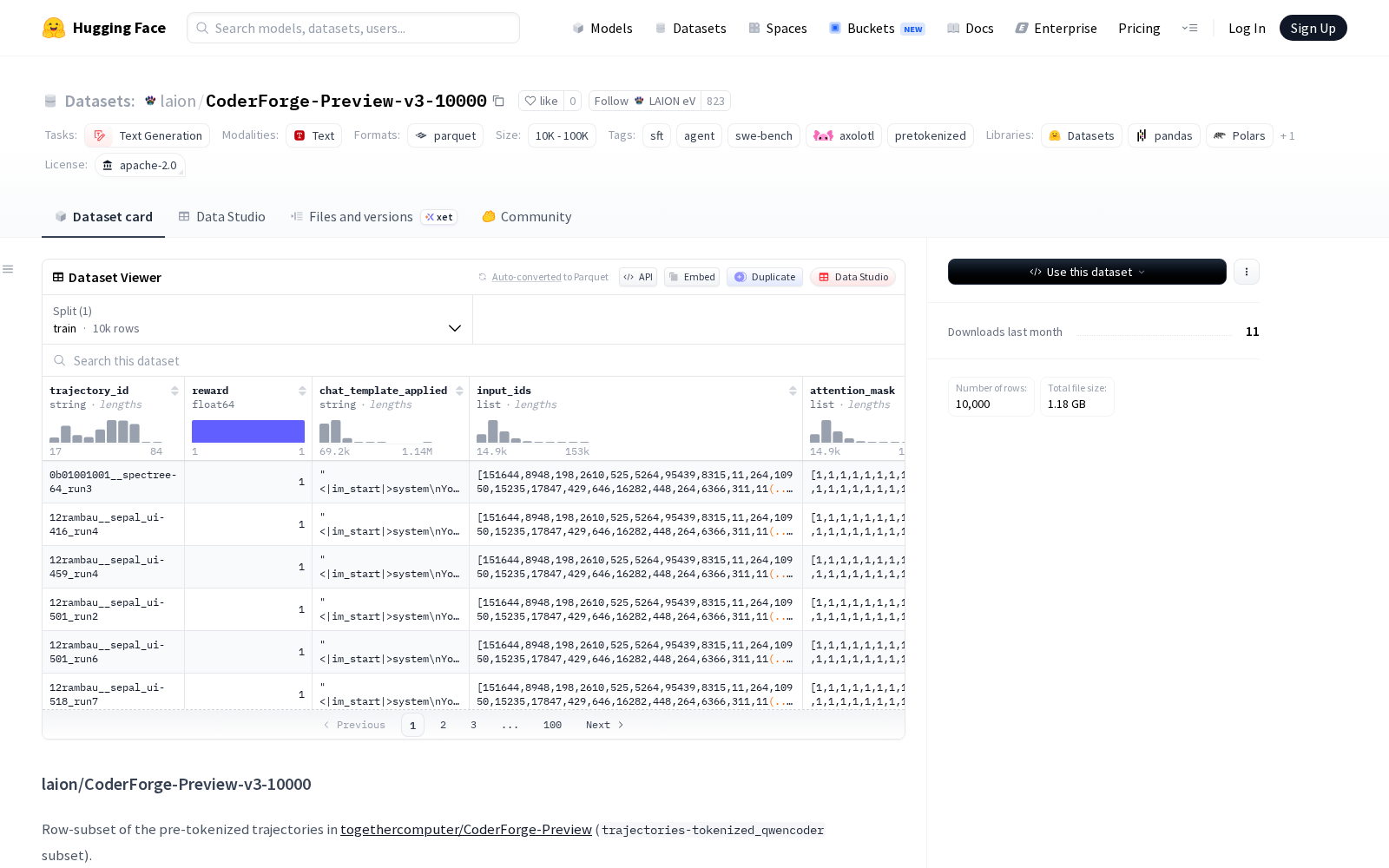
LAION eV本次发布的数据集CoderForge-Preview-v3-10000,是从togethercomputer/CoderForge-Preview数据集的trajectories-tokenized_qwencoder子集中抽取的10,000行预标记数据子集。该数据集专为Qwen3模型设计,包含input_ids、attention_mask、labels等多个标准训练字段,适用于各类文本生成任务。数据来源于R2E_Gym, SWE_Rebench, SWE_Smith, filtered_reward1四个不同的高质量数据源,并通过种子为42的确定性采样生成,数据一致性与可复现性得到充分保障。值得关注的是,该数据集采用原生预标记格式,可直接导入axolotl训练框架使用,同时支持最高32768 tokens的长序列处理,可满足长文本代码生成、全项目代码理解等复杂场景的训练需求。
从产业应用价值来看,预标记数据集可免去研发团队在数据清洗、标注、格式转换等环节的大量重复劳动,大幅压缩大模型微调的前期准备周期,降低研发成本。该数据集的典型应用场景覆盖多个AI研发领域:可用于Qwen3系列模型的代码生成、代码推理能力优化,支撑智能编程助手的功能迭代;可训练长序列代码理解模型,用于企业级代码库的智能语义检索、代码漏洞自动化检测;也可用于低代码/无代码平台的自然语言转代码功能升级,降低非专业开发者的软件研发门槛。
从行业层面来看,本次数据集的开放是开源AI数据领域面向垂类大模型做定向优化的典型实践,为AI训练数据的场景化、标准化开放提供了参考样本,也进一步降低了代码大模型领域的研发门槛,助力更多中小团队参与生成式AI应用创新,对推动训练数据要素的高效流通与价值释放具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)