

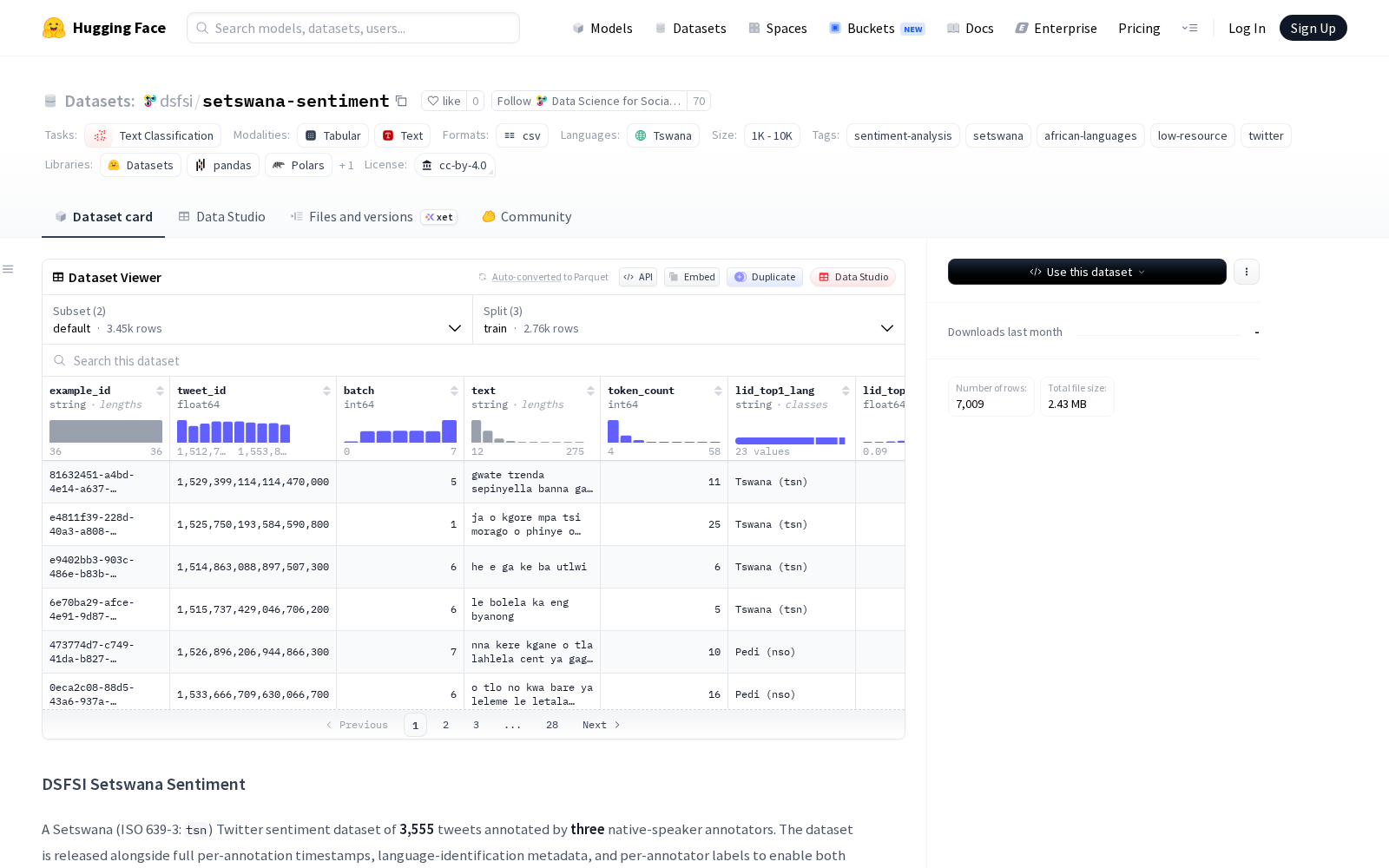
当前全球自然语言处理(NLP)技术已在智能客服、舆情分析、公共服务数字化等场景实现规模化落地,但行业普遍面临低资源语言数据供给不足的痛点:全球现存7000余种语言中,超过95%的公开标注数据集集中在英语、汉语等使用人口过亿的高资源语言,非洲、拉美等区域的上千种本土语言长期缺乏标准化标注数据,直接制约了当地数字普惠服务的覆盖进度。专注于推动数据技术赋能边缘群体的研究机构Data Science for Social Impact(简称DSFSI)本次发布的数据集setswana-sentiment,正是针对低资源语言NLP研发需求推出的专项数据资源。DSFSI Setswana Sentiment 是一个用于情感分析的数据集,包含 3,555 条 Setswana 语(ISO 639-3: `tsn`)的 Twitter 推文,由三位母语为 Setswana 的标注者进行标注。数据集提供了完整的标注时间戳、语言识别元数据以及每位标注者的标签,支持下游建模和标注质量研究。数据集分为训练集(2,762 条)、验证集(346 条)、测试集(346 条)和一个完整配置(3,555 条),其中训练/验证/测试集仅包含三种核心情感类别(积极、消极、中性),并按共识标签以 80/10/10 的比例分层分配。数据集还包含标注者标签、时间戳、共识类型等元数据,适用于情感分类器的训练与评估,以及标注质量研究。数据预处理包括用户名、提及、URL 等敏感信息的替换,以及大小写归一化,从源头上规避了数据应用中的隐私合规风险。
从应用价值来看,该数据集可广泛覆盖塞茨瓦纳语使用区域的多类数字化需求:塞茨瓦纳语是博茨瓦纳的官方语言,同时也是南非、纳米比亚等国的通用少数民族语言,使用总人口超过千万,该数据集可支撑本土社交平台舆情监测、公共政策民意反馈收集、本土电商用户评论分析、塞茨瓦纳语智能客服语义识别等多类NLP应用研发;对于学术研究领域而言,数据集附带的多标注者原始标签、时间戳等元数据,也可为低资源语言标注质量评估、跨时间维度语义演化研究等方向提供数据支撑。
数据集的主要局限性包括 Twitter 数据的特定性、标签分布不均衡(消极和中性标签占主导),以及标注时间跨度对一致性的影响,从业者可根据自身应用场景筛选适配。数据集采用 Creative Commons Attribution 4.0 International (CC BY 4.0) 许可发布,商用、学术研究场景均可免费使用,仅需标注来源即可。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)