

作为支撑Stable Diffusion等现象级AI产品训练数据集的核心研发方,非盈利机构LAION eV长期以来是全球AI开源数据生态的重要建设者,其发布的多模态、大语言模型相关数据集,一直是全球AI开发者降低训练成本、加速产品迭代的核心公共资源。近年来,随着大模型落地逐步从通用问答转向垂直场景的功能性应用,工具调用能力已成为智能体(Agent)、企业级智能助手、行业垂类大模型的核心能力门槛,而适配不同大模型格式的高质量标注微调数据,始终是行业供给较为紧缺的核心资源。
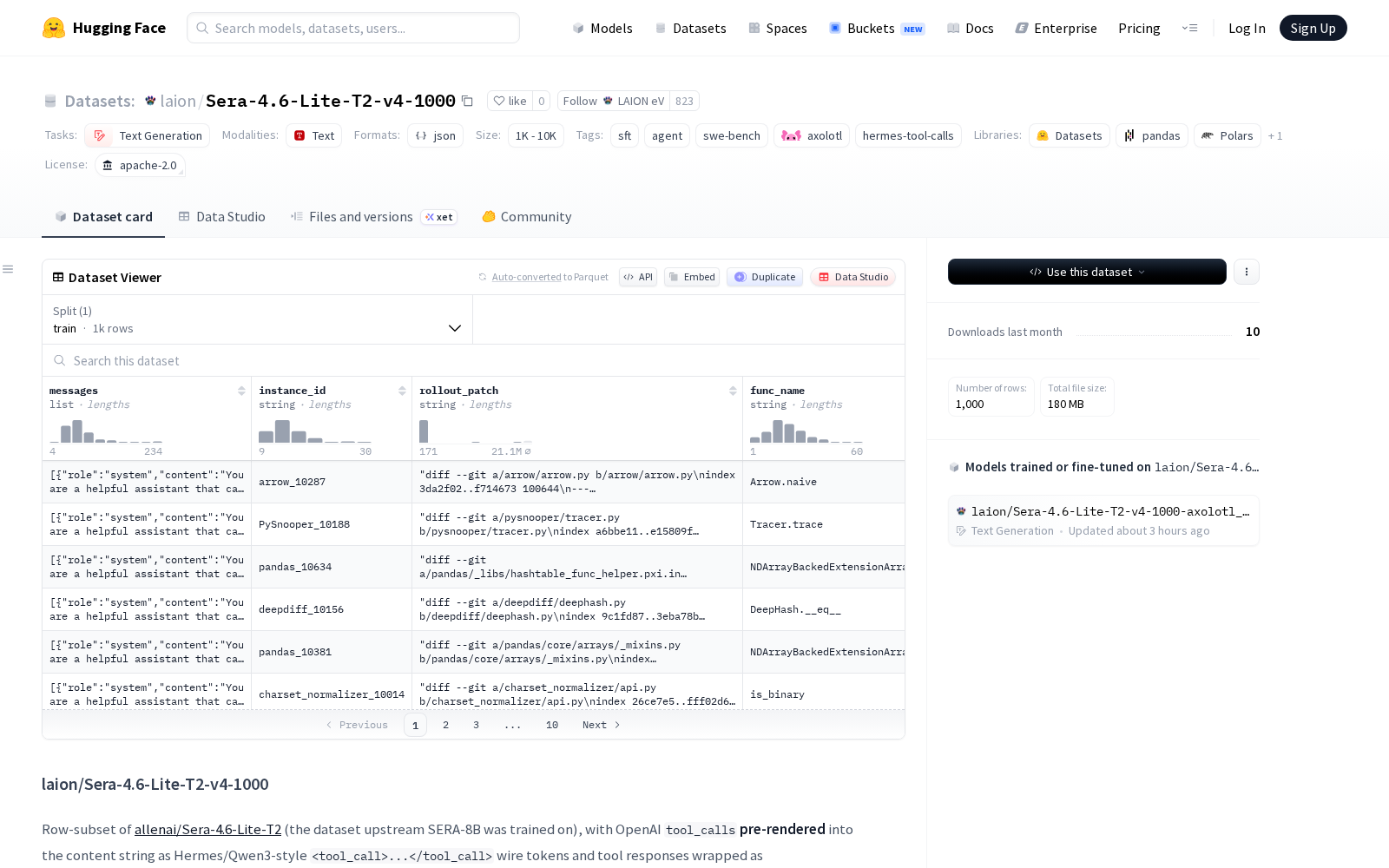
LAION eV本次发布的数据集Sera-4.6-Lite-T2-v4-1000,正是针对工具调用场景的微调需求推出的轻量化开源数据集。该数据集是allenai开源Sera-4.6-Lite-T2数据集的官方精选子集,仅包含1,000条经过格式标准化的高质量标注数据(源数据集总规模为36,083条),尤其适合中小开发者、研究团队快速验证工具调用能力的训练效果。
相比源数据集,本次发布的子集最大价值在于完成了格式的标准化适配:其将OpenAI原生的`tool_calls`格式预渲染为当前Hermes、Qwen3等主流开源大模型通用的`
该数据集采用通用的JSONL格式存储,每条数据包含`messages`列表,列表中每条消息均标注了`role`(分为system、user、assistant三类)、`content`和`train`字段,工具观察内容统一以`role: user`身份搭配`
从行业应用来看,该轻量化数据集的典型使用场景覆盖多个维度:个人开发者可借助其快速跑通工具调用大模型的微调流程,验证产品原型可行性;中小团队可基于其快速迭代轻量级智能体、行业工具助手等产品,大幅减少初始训练的算力投入;高校及培训机构也可将其作为大模型微调实训的教学样本,降低教学环节的数据获取门槛。若开发者验证效果符合预期,可进一步基于全量的Sera-4.6-Lite-T2数据集完成更高精度的模型训练。该数据集的发布,也进一步丰富了全球开源大模型微调数据生态,对推动工具调用类AI应用的普惠化落地具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)