

作为全球领先的非盈利开源AI数据集组织,LAION eV此前推出的多类大规模训练数据集已支撑了多款主流生成式AI模型的研发落地,是全球AI开源生态的核心数据供给方之一。当前代码大模型已成为AI落地企业级服务、AI原生应用开发的核心技术赛道,高质量、标准化的代码类训练数据一直是行业稀缺的核心资源,直接决定了代码大模型的生成准确性、逻辑合理性与场景适配能力。
2026年4月23日,LAION eV正式面向全球AI开发者与科研机构发布CoderForge-Preview-v3-3160数据集,首发上架至Hugging Face平台,覆盖自然语言处理、代码生成两大核心应用领域。
LAION eV本次发布的数据集CoderForge-Preview-v3-3160,laion/CoderForge-Preview-v3-3160 是一个预分词轨迹数据的子集,源自 togethercomputer/CoderForge-Preview 数据集中的 trajectories-tokenized_qwencoder 子集。该数据集包含 3,160 行数据,是从 4 个源数据块(R2E_Gym、SWE_Rebench、SWE_Smith、filtered_reward1)中确定性采样(种子为 42)得到的。数据格式为 Qwen3 的原生预分词数据(分词器与 Qwen2.5-Coder / Qwen3-Coder / Qwen3-8B 共享),可直接适配通义千问代码大模型系列的训练需求,无需开发者额外完成分词预处理工作。每行数据包含以下字段:input_ids(int32 列表)、attention_mask(int8 列表,全为 1)、labels(int64 列表,已应用 -100 掩码)、chat_template_applied(字符串,用于调试)、trajectory_id(字符串)、reward(float64)和 source(字符串,固定为 togethercomputer/CoderForge-Preview/trajectories-tokenized_qwencoder)。自带的预标注标签与奖励分字段,可大幅降低开发者数据清洗、标注的前置工作量,提升训练效率。
该数据集适用于 axolotl 框架,配置时需指定 chat_template 为 chatml,并设置 sequence_len 为 32768(因上游数据序列可能超过 80k 标记,axolotl 会进行截断)。从应用场景来看,该数据集可支撑代码大模型的指令微调、奖励模型训练、对齐训练等全流程研发需求,也可用于自然语言转代码、代码语义理解、代码纠错、代码解释等NLP+代码交叉领域的任务训练,同时可为高校、科研机构的代码大模型性能评测、训练方法论研究提供基准测试数据。
该数据集的发布进一步丰富了全球开源代码训练数据的供给池,降低了中小研发团队、科研机构训练代码大模型的门槛,也为AI训练数据要素的标准化开放、流通提供了可参考的实践样本,对推动代码生成领域的技术普惠与创新落地具有积极意义。
Dataset card内容:
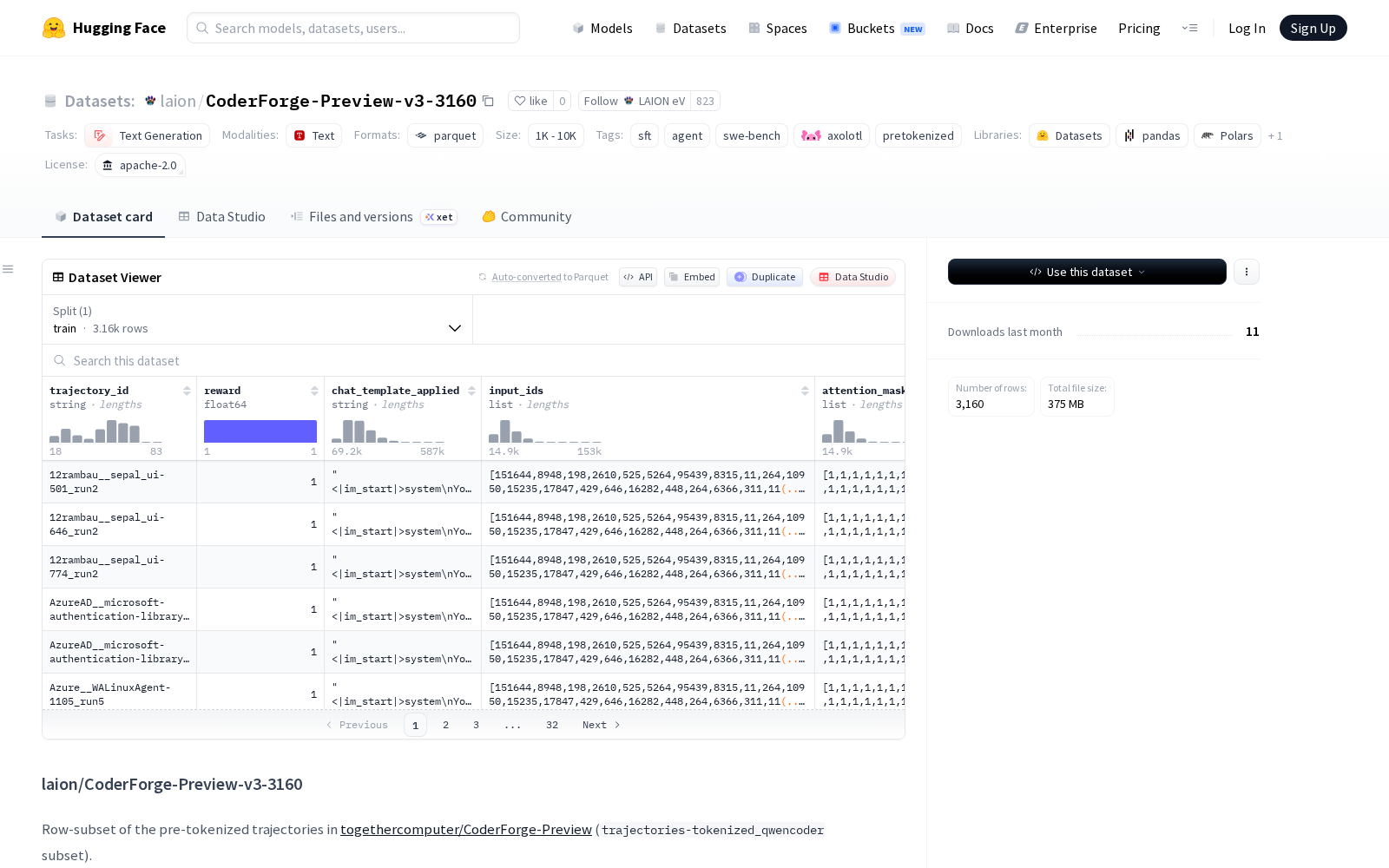
Files and versions内容:



_1769672084863.jpg)