

当前代码大模型已成为生成式AI落地的核心赛道之一,高质量、标准化的垂类训练数据集,是决定代码大模型生成准确率、逻辑合理性、场景适配性的核心基础资源。作为全球知名的非盈利开源AI数据集建设机构,LAION eV曾推出支撑生成式AI产业发展的多款标杆级公开数据集,在全球AI开源社区拥有极高的行业影响力,此次发布的CoderForge-Preview-v3-31600是其在代码AI领域的最新开源成果。
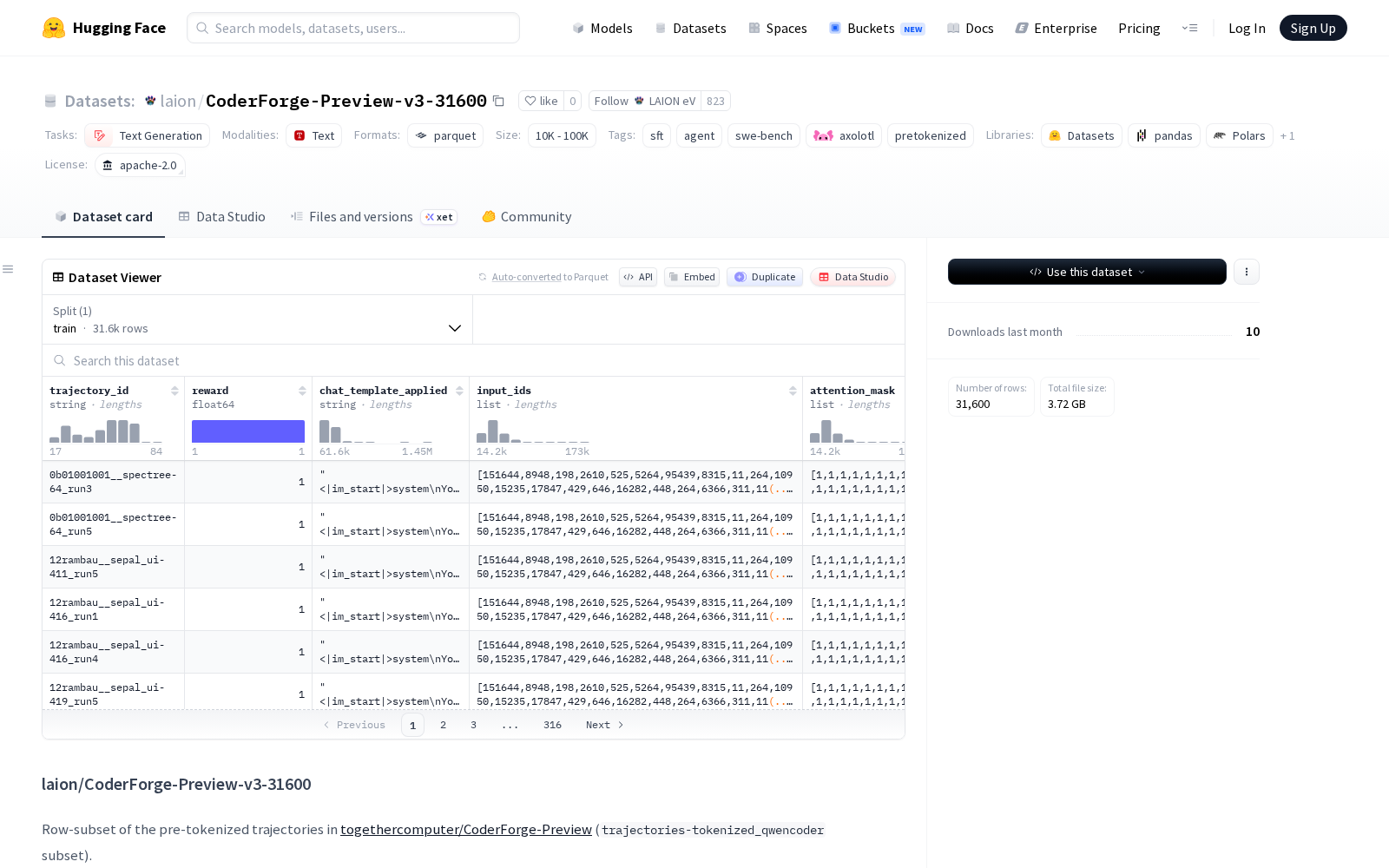
LAION eV本次发布的数据集CoderForge-Preview-v3-31600,是从togethercomputer/CoderForge-Preview数据集中提取的预分词轨迹子集(trajectories-tokenized_qwencoder 子集)。该数据集包含31600行经过标准化处理的训练数据,提取自包含155144行数据的原始数据源,样本覆盖R2E_Gym、SWE_Rebench、SWE_Smith、filtered_reward1四大代码类基准数据源,通过种子为42的确定性采样方式从四大源数据集拼接池中抽取,保障了样本的代表性和可复现性。
从数据格式来看,该数据集为Qwen3适配的本地预分词数据,分词规则与Qwen2.5-Coder、Qwen3-Coder、Qwen3-8B等热门开源代码大模型共享分词器,开发者可直接调用无需额外预处理。单条数据包含六大核心字段:为int32列表形式的input_ids为模型输入的编码序列、int8列表形式的attention_mask(全为1)用于控制模型注意力机制、int64列表形式的labels已应用-100掩码可直接适配监督微调训练的损失计算、字符串格式的chat_template_applied可用于调试校验、字符串格式的trajectory_id用于样本溯源、float64格式的reward字段为样本质量评分可直接用于大模型偏好对齐训练,source字段固定为togethercomputer/CoderForge-Preview/trajectories-tokenized_qwencoder,方便开发者追溯原始数据源。
从应用价值来看,该数据集可广泛应用于各类文本生成任务,尤其适配Qwen3系列代码大模型的训练、微调与对齐环节。下游开发者可基于该数据集开发多类代码AI应用:面向企业研发场景的智能代码助手,可实现自动代码补全、语法错误自动修复、代码注释自动生成、跨编程语言代码迁移等功能;面向网络安全场景的代码安全审计模型,可快速识别代码中的漏洞风险;面向开发工具赛道的低代码/无代码平台,可实现自然语言转代码的能力升级;面向教育场景的编程辅助工具,可实现智能解题、代码优化建议等功能,大幅降低不同领域开发者的代码AI研发门槛。
此次该数据集在HuggingFace平台首发,进一步丰富了全球开源代码训练数据集的供给,为中小研发团队降低了代码大模型的训练数据获取成本,也为代码大模型训练的标准化、可复现性提供了参考样本,对推动开源AI生态建设、加速代码AI场景落地具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)