

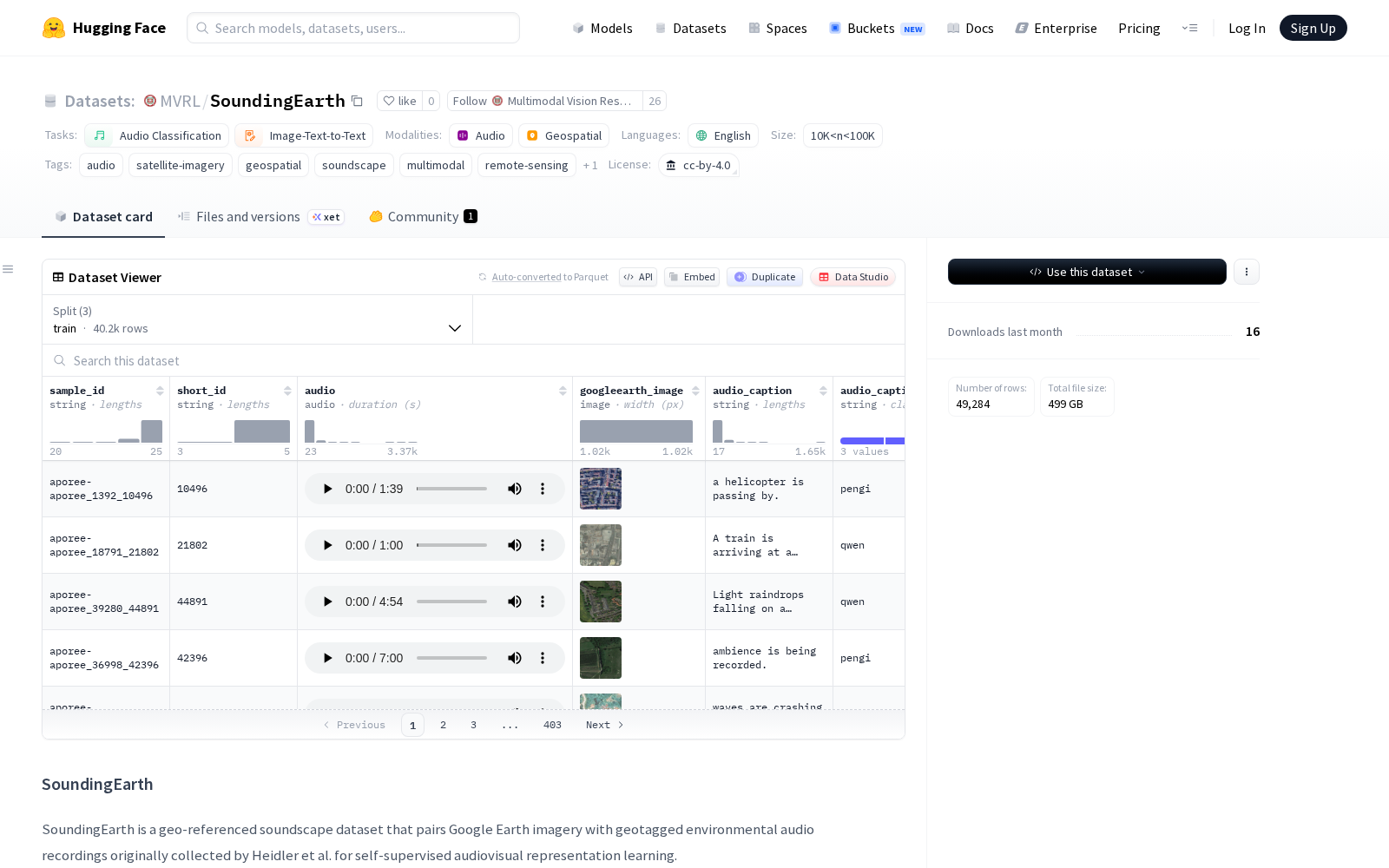
Multimodal Vision Research Laboratory @ WashU本次发布的数据集SoundingEarth,该数据集是一个多模态数据集,包含音频、图像和文本数据。主要特征包括音频文件(采样率为32kHz)、谷歌地球图像、音频字幕及其来源、梅尔频谱特征(形状为5x1x1001x64的浮点数组)、基于LLaVA模型的谷歌地球图像字幕、经纬度坐标以及录制日期。数据集分为训练集(40,241个样本)、验证集(3,242个样本)和测试集(5,801个样本),总大小约为498GB。该数据集适用于多模态学习任务,如音频-图像关联分析、地理空间音频识别等。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)