

在全球多语言大模型研发、跨语言内容治理需求持续爆发的当下,高质量标注的多语言NLP数据集已成为AI研发领域的核心稀缺资源。作为北欧地区领先的公共文化数字化研究机构,挪威国家图书馆(Nasjonalbiblioteket)旗下AI实验室长期聚焦多语言自然语言处理、文化遗产数据的AI化开放,其发布的多语言数据集已被全球多个AI研发团队采用。
2026年4月27日,该实验室正式在HuggingFace平台首发bifrost-translation-source-classifier-dataset(Bifrost翻译源分类器数据集),面向全球AI研发者开放使用。查看bifrost-translation-source-classifier-dataset
据公开信息显示,该数据集是专门为训练翻译源分类器打造的标注数据集,所有样本均为英文文本,标签体系覆盖两类内容:一类标注翻译文本的原始来源语言,另一类以原生英文文本作为控制组标注为“en”,核心目标是帮助AI模型学习识别不同语言翻译为英文后残留的文化表达、语言风格特征。本次开放的数据集共覆盖180种语言,每种语言均配置10000条训练样本、1000条验证样本和1000条测试样本,总样本量达216万条,数据来源分别为HuggingFaceFW/finetranslations的翻译文本库和HuggingFaceFW/fineweb的原生英文文本库。数据集共设三个核心字段:text字段存储字符串类型的英文文本内容,label字段存储整型的类别ID,language字段存储字符串格式的源语言代码,可直接适配主流大模型的微调训练流程。
从应用场景来看,该数据集可广泛支撑多个跨语言NLP领域的研发需求:在跨境内容治理场景中,可用于检测翻译内容的原始来源语言,辅助识别跨境信息的传播路径、溯源虚假信息源头;在跨语言文本分类场景中,可支撑多语言客服工单分类、跨境电商用户评论情感分析、全球数字图书馆内容归类等业务需求;在机器翻译优化场景中,可帮助翻译模型识别不同语种的翻译风格特征,降低翻译腔、提升译文的自然度;此外还可为文化语言学、跨文化传播等领域的研究提供大规模标注数据支撑。
业内人士指出,当前全球多语言NLP数据集普遍存在覆盖语种少、标注维度单一、样本量不足等问题,本次挪威国家图书馆AI实验室开放的数据集,不仅填补了180种语言翻译源分类标注数据的空白,也为数据要素市场中公共文化数据的开放共享提供了参考样本,对推动全球跨语言AI技术落地、促进数字文化资源的全球互通具有积极意义。
Dataset card内容:
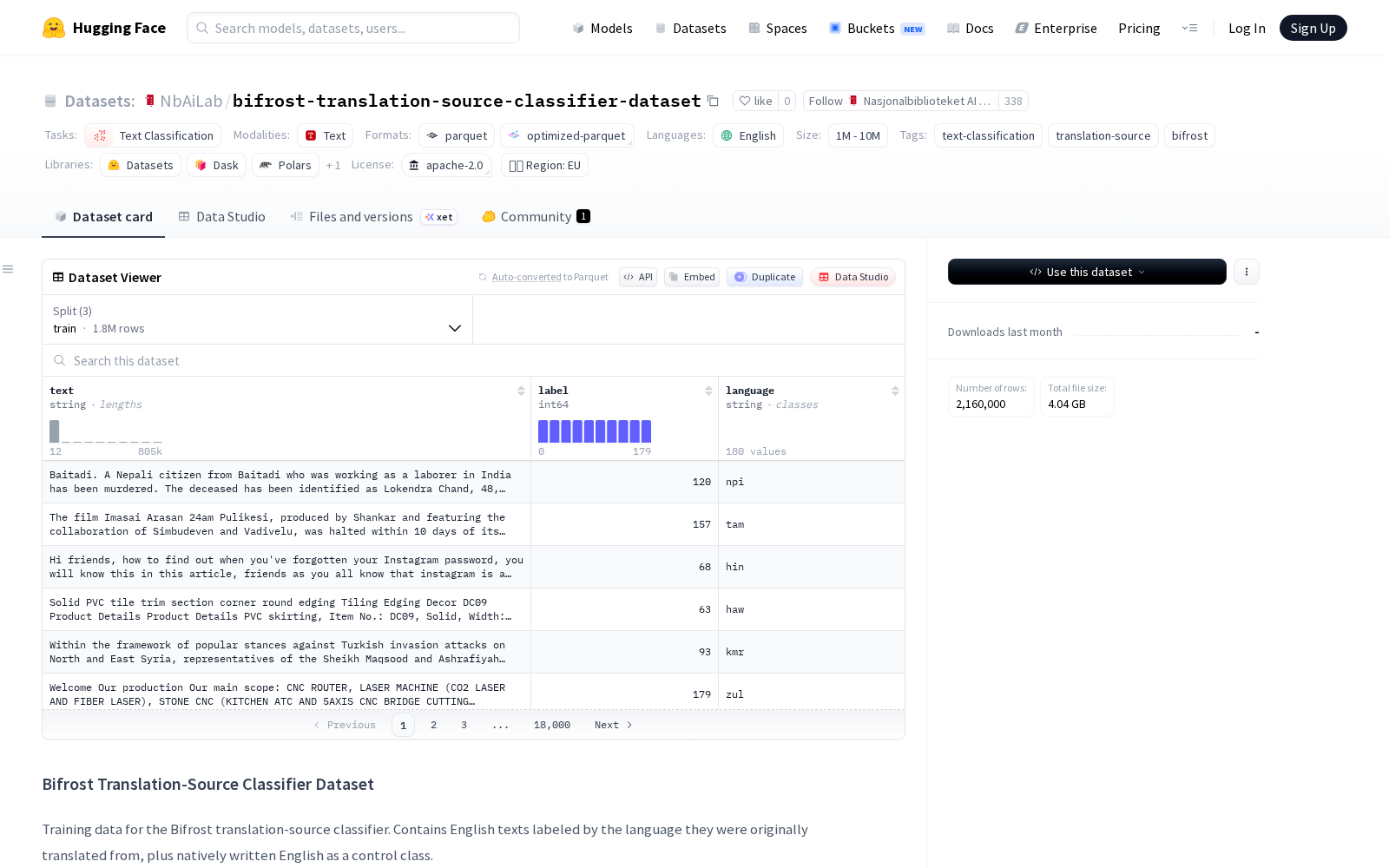
Files and versions内容:



_1769672084863.jpg)