

当前AIGC赛道中文生视频技术迭代速度加快,但现有模型普遍存在3D空间逻辑混乱、几何一致性不足、镜头运动不符合物理规律等痛点,缺乏标准化的训练与评估提示数据集已成为制约3D感知文生视频技术落地的核心瓶颈之一。正是瞄准这一行业需求,微软于2026年4月29日在HuggingFace平台正式发布World-R1提示词数据集,配套研究论文《World-R1: Reinforcing 3D Constraints for Text-to-Video Generation》同步上线。
作为全球首个专门面向文本到视频世界模拟场景设计的提示词数据集,World-R1覆盖静态环境、动态场景、摄像机感知视频生成三大类场景的英文提示词,核心定位是为文生视频模型在3D约束、运动约束条件下的后训练、效果评估与技术分析提供标准化基准素材。
本次公开的数据集共提供两类配置版本,可适配不同研发需求:其一为final版本,采用基础提示词分割规则,可直接用于模型训练、测试以及动态场景正则化场景,包含2,468个训练样本、42个测试样本和500个动态样本;其二为enhanced版本,在基础版本之上扩展了提示词变体,补充了更丰富的场景细节描述与明确的摄像机运动指令,包含2,651个训练样本、300个测试样本和515个动态样本。所有样本均对应唯一的稳定提示标识符(id)与提示字符串(prompt),方便研发人员匹配训练与测试结果。
从应用方向来看,World-R1可覆盖多个AIGC核心研发场景:在文生视频赛道,可用于通用文生视频模型的后训练阶段,强化模型对3D空间逻辑、运动约束的理解,减少生成内容中的穿模、空间错乱等问题;在3D感知视频生成领域,可作为统一的评估基准,用于横向对比不同模型的几何一致性表现、镜头运动还原度;此外还可支撑3D感知强化学习、摄像机感知提示条件训练、动态场景正则化、虚拟世界模拟、数字孪生场景生成等多个方向的研究工作。需要注意的是,本次公开的数据集仅包含文本提示词内容,不附带生成视频、奖励注释、人类偏好标签或模型检查点,研发人员可灵活搭配自有模型、奖励机制开展相关研究,使用门槛较低。
从数据要素价值的角度来看,细分场景的标准化训练数据集是AIGC技术迭代的核心基础设施,本次World-R1数据集的公开,将有效降低3D感知文生视频领域的研发门槛,推动行业形成统一的评估标准,为文生视频技术从“可用”向“高保真、强空间逻辑”的升级方向提供核心数据支撑,也为后续虚拟拍摄、数字孪生、元宇宙内容生成等落地场景的技术成熟打下基础。
Dataset card内容:
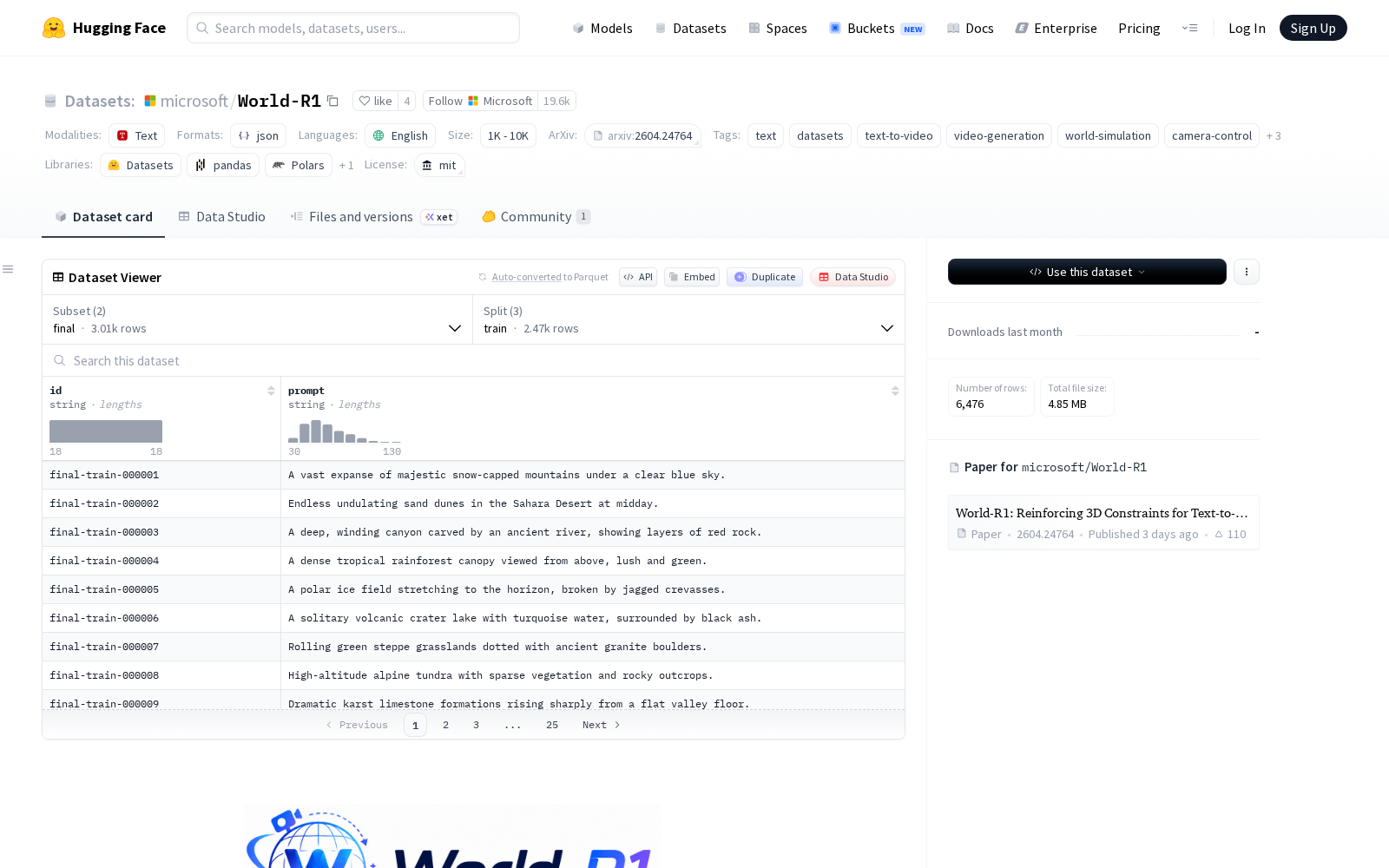
Files and versions内容:



_1769672084863.jpg)