

当前大语言模型与NLP应用快速落地过程中,垂直领域高质量、低噪声的标注语料供给始终是行业共性短板,尤其是教育、科研类语料,普遍存在来源混杂、内容规范性不足、版权风险高等问题,直接影响下游模型的输出精度与应用合规性。近日MLX Community正式对外发布的tnc-archive学术类数据集,正是填补了细分场景下的优质语料供给空白。
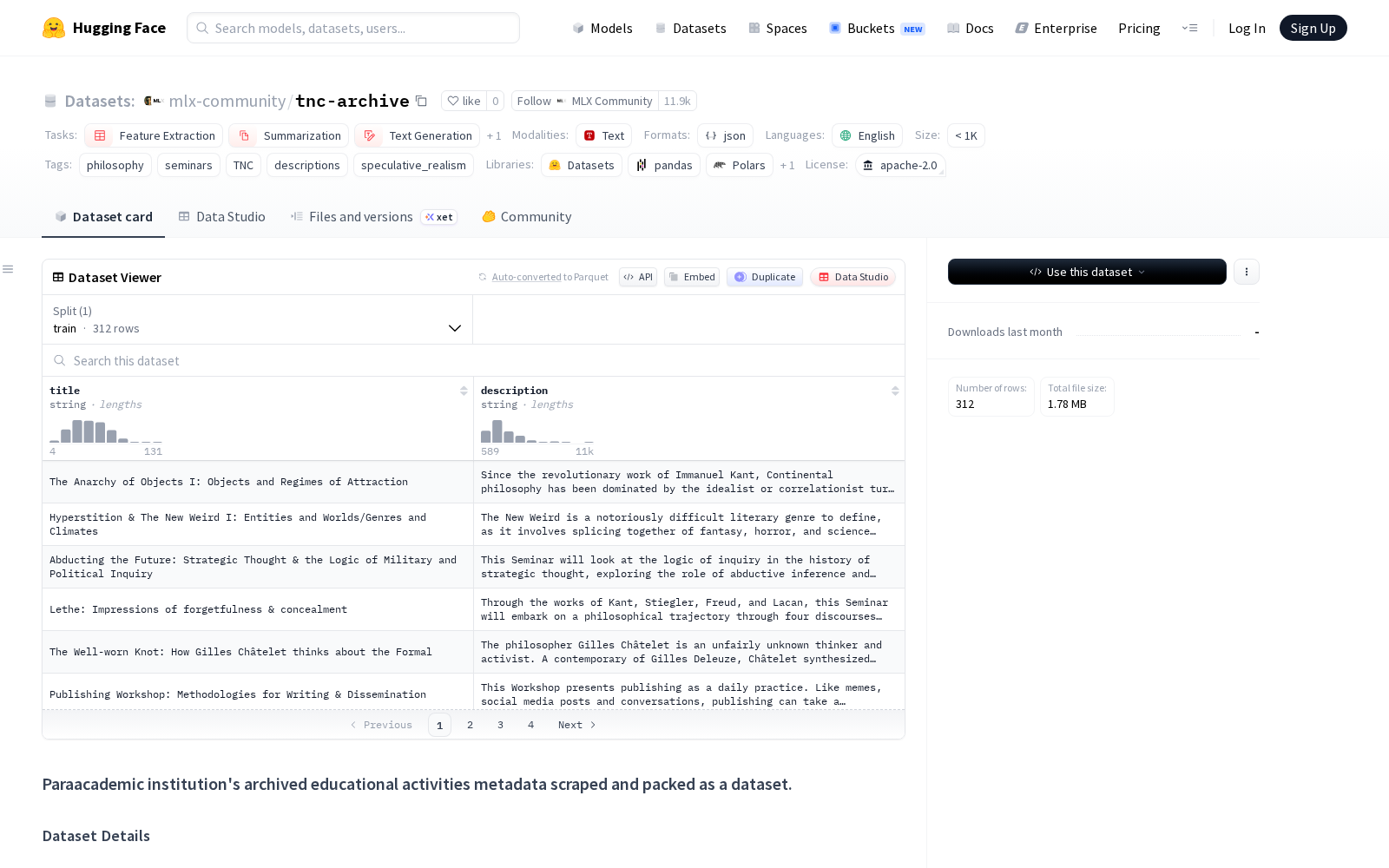
据介绍,tnc-archive数据集的所有内容均抓取自全球前沿跨学科研究机构“新研究中心与实践”(The New Centre for Research & Practice)的公开研讨会档案,其中的标题、摘要描述全部由负责或主持相关研讨会的讲师亲自撰写,100%为人工原创内容,部分条目还配套了对应的参考阅读材料,学术语言规范度、内容专业度远高于普通爬虫获取的公开语料。该数据集整体规模较小,条目总量少于1000条,但几乎无噪声干扰,语料质量优势突出,数据全部来自该中心的公开档案页面,合规性也得到充分保障。
从适用方向来看,tnc-archive可支持文本生成、自动摘要、文本分类等多种基础NLP任务的微调训练,尤其适配三大类落地场景:一是教育元数据生成领域,可用于训练学术研讨会、线上公开课的标准化元数据自动生成模型,降低教育内容归档的人工成本;二是RAG检索增强系统的参考语料库,可为科研辅助类AI工具提供权威的前沿研究内容支撑,提升知识问答的准确性;三是前沿思想研究领域,研究者可通过该数据集开展主题聚类、研究趋势演化分析等工作,挖掘跨学科研究的前沿动态。
需要注意的是,该数据集目前也存在一定应用限制:一方面收录的研讨会主题相对小众,覆盖的研究领域范围有限;另一方面仅开放了研讨会的标题与摘要内容,研讨会的完整音视频、全文资料等实际内容暂未对外开放,适用场景存在一定边界。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)