

当前AIGC产业步入垂直场景落地深水区,虚拟角色生成、AI Agent开发、轻量型结构化输出工具等赛道需求快速攀升,但中小团队往往面临大参数模型调用成本高、小参数模型结构化输出准确率低、细分领域微调数据稀缺等痛点。针对这一行业共性需求,AI研发商flammen.ai正式发布垂直场景专用微调数据集flame-kindling-v1,该数据集是目前少数面向角色设计生成+JSON模式微调场景的轻量化SFT数据集。
flame-kindling-v1定位为小型、专业化的监督微调数据集,核心目标是仅通过小样本训练,即可将3B级别的轻量型指令模型微调为能够从自由文本种子生成严格JSON模式的角色设计器。该数据集共包含400组(种子→DesignedFlame)配对标注数据,全量数据通过Claude Sonnet 4.5工具生成,并经过三重质量校验:首先通过pydantic模式完成JSON格式合规性验证,其次通过名称去重、特征嵌入相似性去重排除重复样本,最后由Qwen3.5-27B大模型完成内容连贯性评估,整体数据质量满足小样本微调的精度要求。
数据集采用行业通用的ChatML风格消息格式,每条记录包含系统提示、用户输入和助理输出三类JSON对象,其中助理输出的JSON严格遵循`DesignedFlame`标准模式,覆盖名称、性别、性取向、语言、起源地、兴趣等多个核心角色属性字段,可直接对接各类角色管理系统。目前该数据集支持32种语言,覆盖多元性别、性取向、地区和角色原型,能够适配不同文化背景下的角色生成需求。
从应用场景来看,尽管flame-kindling-v1样本规模仅400条,但其垂直精准的标注逻辑,不仅能够直接适配flammen.ai官方的Create-a-Flame角色生成流程,还可为大量轻量型AI项目提供低成本训练底座:游戏研发团队可基于该数据集微调小模型,快速批量生成NPC标准化角色档案;虚拟社交、元宇宙平台可依托该模型能力实现用户自定义角色的结构化转译;AI Agent开发团队也可将其作为角色人格初始化模块的训练基础,无需投入大量标注成本即可实现结构化角色输出能力。此外,对于所有需要实现轻量型JSON生成能力的AI项目,该数据集也可作为标注样本的参考框架。
官方同时披露了该数据集的当前限制:由于样本量较小,暂不支持高复杂度角色生成需求;全量数据不含NSFW内容,无法适配成人向内容生成场景;数据集存在一定英语偏见,小语种的生成效果仍有提升空间;同时评分校准标准相对宽松,高精度需求场景建议额外补充自定义校验规则。
Dataset card内容:
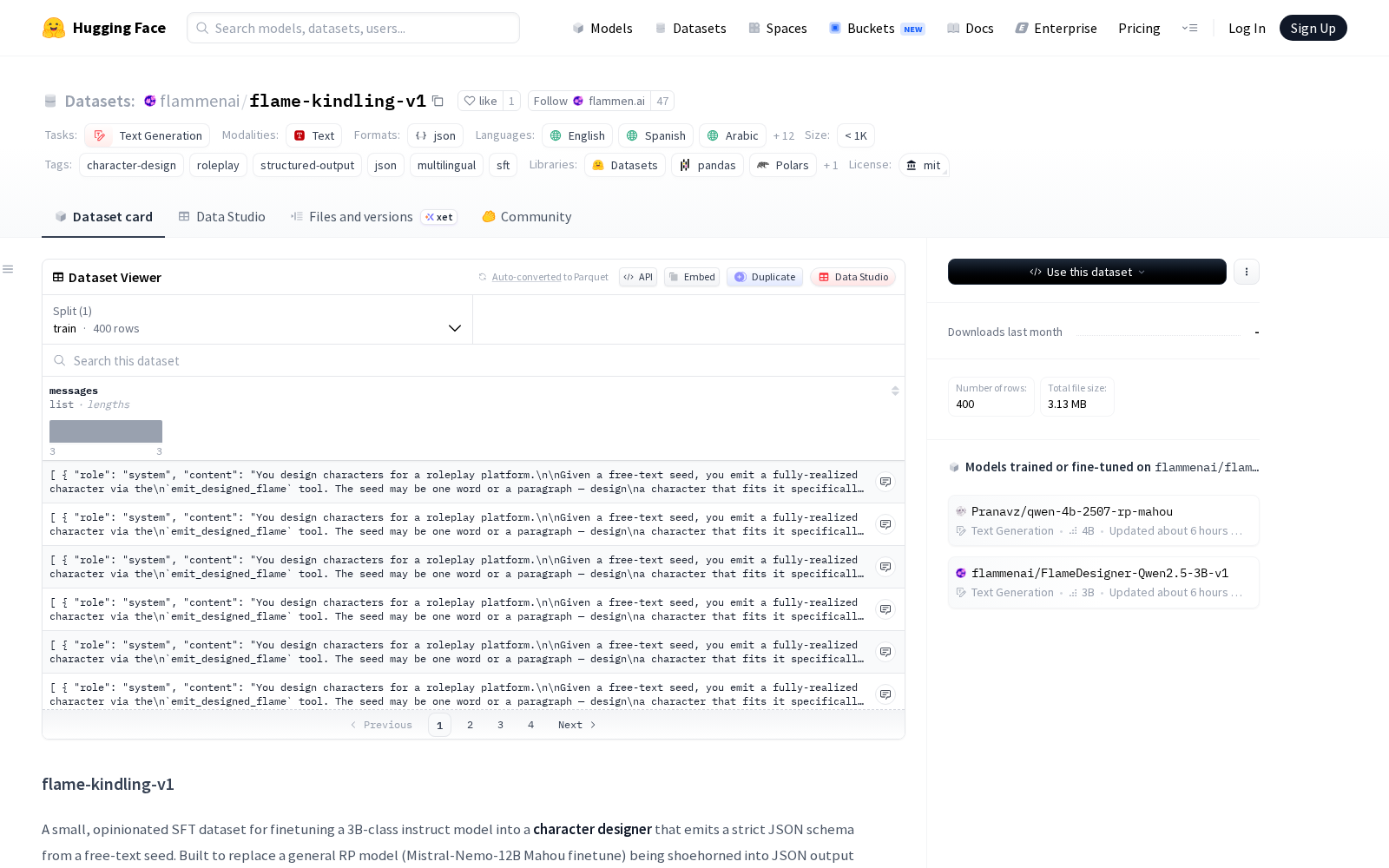
Files and versions内容:



_1769672084863.jpg)