

当前大模型跨领域任务适配、工具调用能力训练的需求快速增长,结构化的「任务需求-对应数据-溯源信息」关联数据集已成为AI研发领域的稀缺公共资源。近日,美国俄亥俄州立大学自然语言处理研究组(OSU NLP Group)正式在HuggingFace平台首发开源D3-Gym数据集,这也是该团队2026年公布的首个面向多学科任务匹配场景的开源数据资源。
本次公开的D3-Gym数据集采用MIT开源许可协议,允许使用者免费商用、修改与二次分发,大幅降低了科研机构、AI企业及个人开发者的使用门槛。数据参数方面,该数据集当前版本包含1个训练集,共计329条样本,原始总容量为888712字节,压缩后下载大小为357097字节。
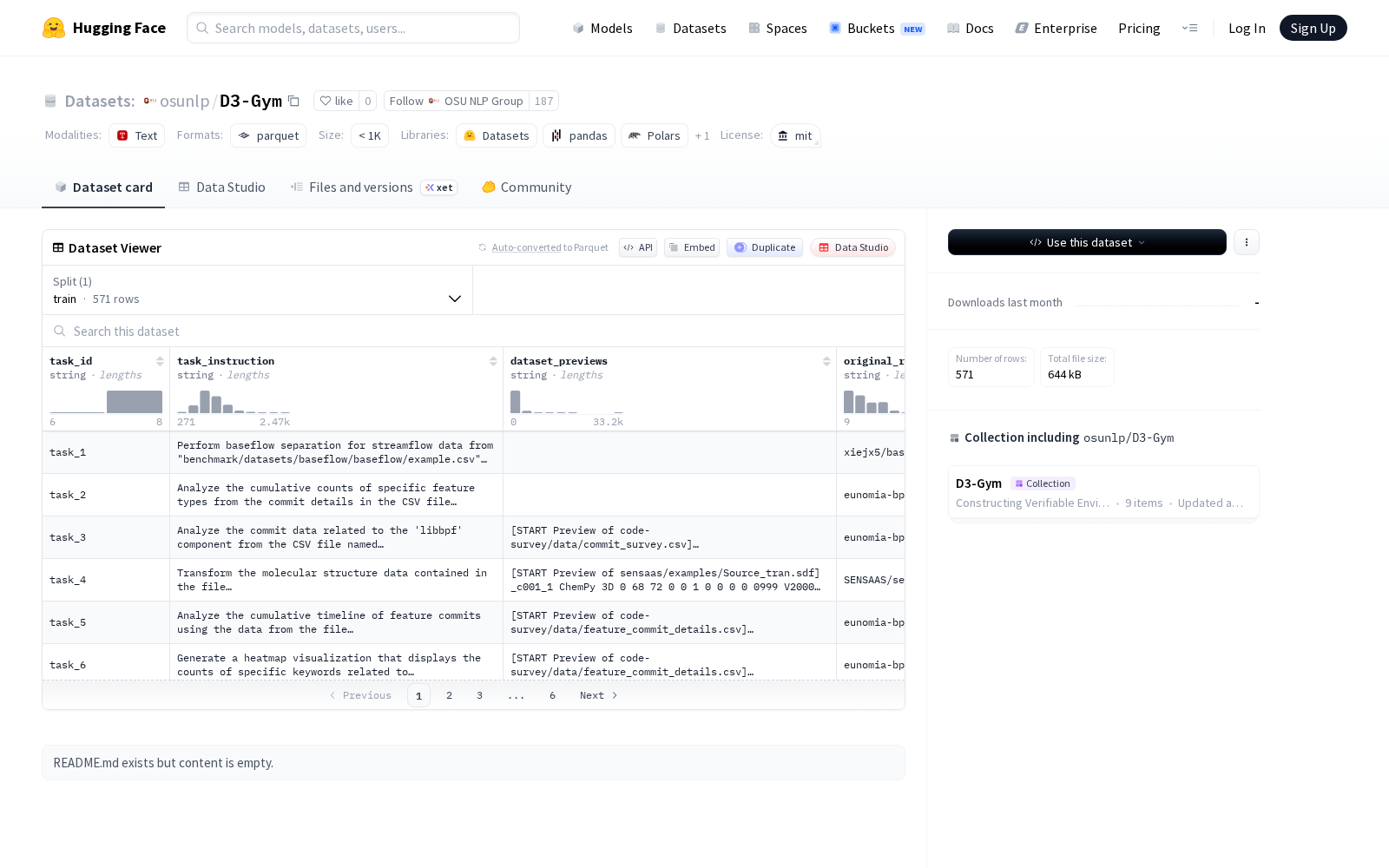
从字段配置来看,D3-Gym构建了完整的任务-数据关联标注体系,共设置5个核心字符串类型字段:task_id为任务唯一标识符,可用于样本的标准化管理;task_instruction为自然语言形式的任务指令,对应具体的任务需求描述;dataset_previews为任务关联的数据集预览信息,可快速判断数据匹配度;original_repo为任务关联数据的原始仓库溯源地址,为数据合规使用提供权属追溯依据;discipline为任务所属的学科分类标签,支持分领域的样本筛选与模型训练。
尽管官方README文档暂未明确说明该数据集的具体研发背景与定向应用场景,但从字段设计来看,其可覆盖多个典型AI研发场景:一是大模型多学科任务理解能力训练,通过不同学科的任务指令与对应数据的关联标注,帮助大模型学习不同领域的任务需求特征,提升跨领域任务响应的准确率;二是数据工具链产品研发,基于任务指令与数据集的匹配关系,可用于开发自动数据集推荐、任务需求自动拆解匹配的效率工具,降低科研人员的数据查找成本;三是开源数据治理研究,数据集自带的原始仓库溯源字段,也可为开源数据的权属追溯、合规流通研究提供样本支撑。
作为AI产业的核心生产要素,高质量开源训练数据集的供给,是降低全行业研发成本、推动中小团队技术创新的重要支撑。本次OSU NLP Group发布的D3-Gym虽然样本规模不大,但其完整的「任务-数据-溯源」字段设计,为后续同类型训练数据集的标准化建设提供了可参考的范式。
查看D3-Gym
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)