

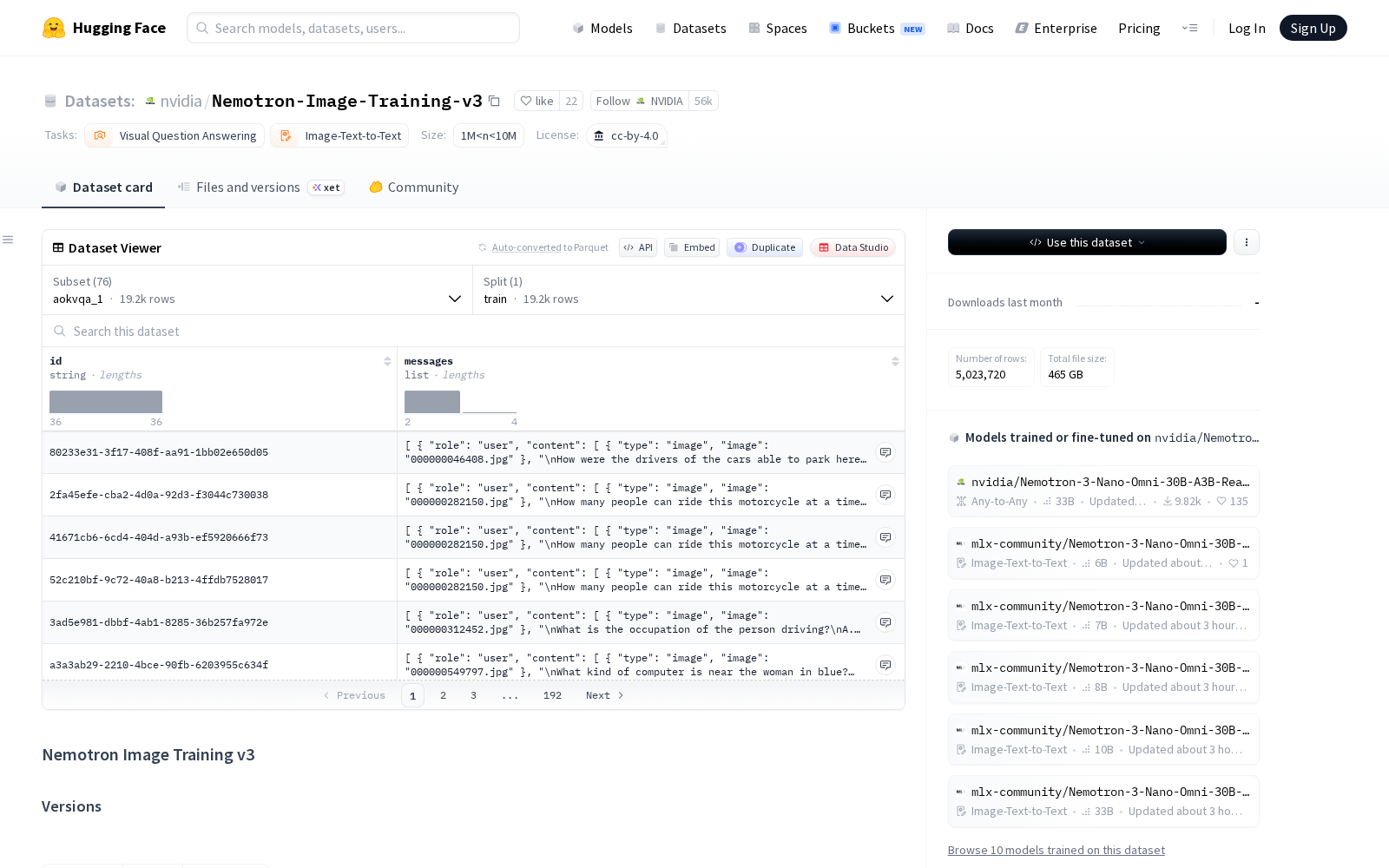
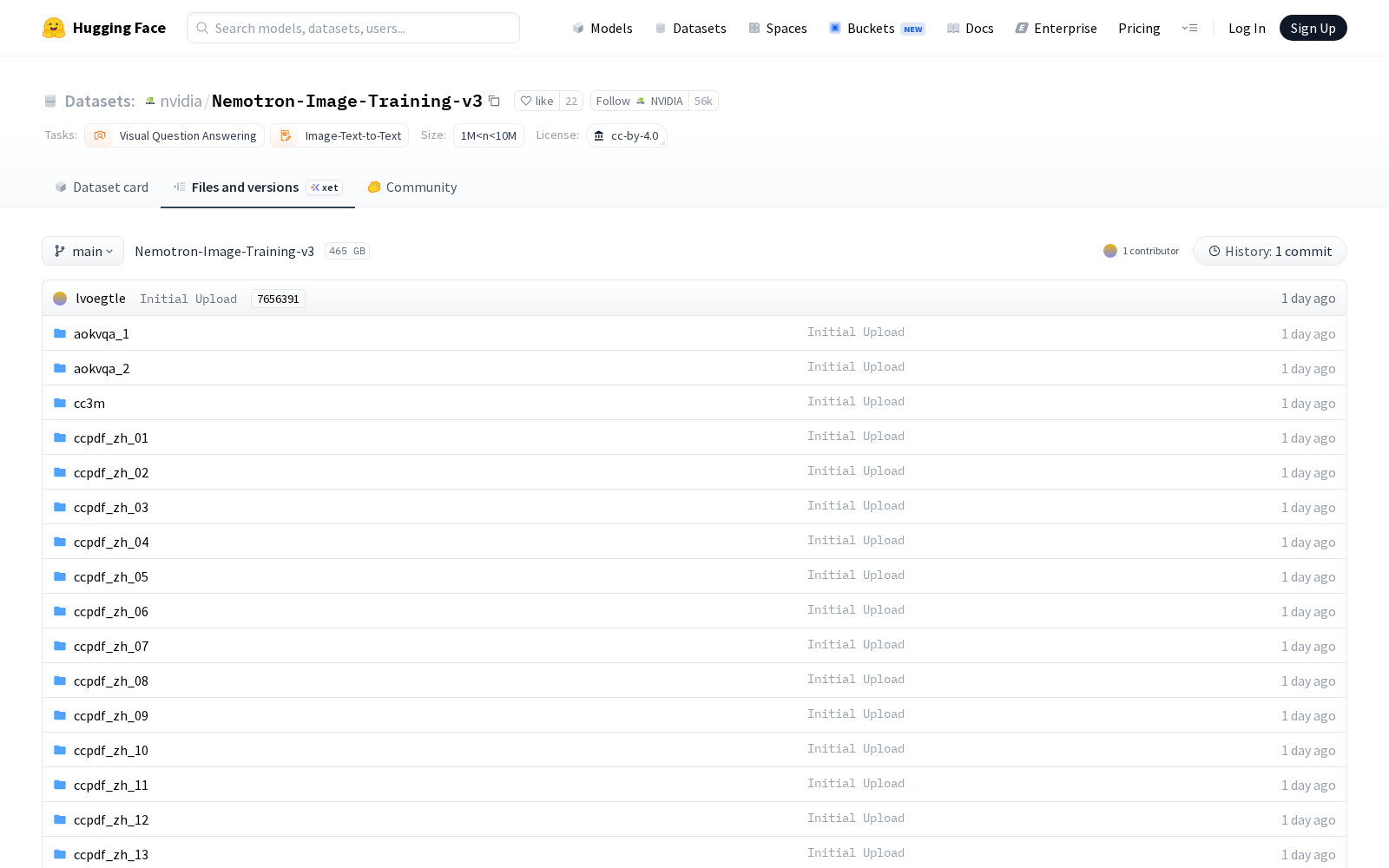
当前多模态大模型已成为全球AI技术落地的核心方向,跨模态理解、推理能力的提升高度依赖高质量、标注规范的训练数据集,而具备规模化、多场景覆盖特性的多模态训练数据,始终是行业供给的核心缺口。近日,NVIDIA正式发布Nemotron-Image-Training-v3多模态图像数据集,作为面向视觉-语言模型训练的专用多模态数据集,该产品于2026年4月28日首发上线HuggingFace平台,为全球AI开发者提供标准化的训练数据支撑。作为前代Nemotron-Image-Training-v2的扩展升级版本,本次发布的v3数据集共包含76个子数据集,总计约690万样本、395.6亿标记(token),数据规模与覆盖场景均较上一代有明显提升。为兼顾数据质量与供给效率,数据集采用人工标注与合成数据相结合的混合来源模式,所有数据统一采用标准化JSONL对话格式存储,每个子数据集均附带独立数据卡片,明确标注数据来源、使用许可与媒体布局信息,大幅降低开发者的数据清洗与合规核验成本。从任务覆盖范围来看,该数据集全面覆盖主流视觉-语言任务类型,包括图像问答(QA)、OCR识别、多模态推理等场景。基于该数据集训练的视觉-语言模型,可广泛应用于多个产业场景:例如工业制造领域的缺陷智能识别与故障原因自动输出、零售行业的商品图文信息自动匹配、政务服务领域的纸质材料智能识别与信息提取、自动驾驶领域的道路场景语义理解、内容创作领域的图文生成效果对齐等,为多模态AI技术的产业落地提供底层数据支撑。在使用许可层面,Nemotron-Image-Training-v3采用CC-BY-4.0开源许可,支持商业与非商业用途使用,开发者仅需自行从上游来源获取对应的图像/视频媒体文件即可开展训练工作。该数据集在技术适配层面也做了针对性优化,三大核心特性大幅降低开发门槛:一是采用结构化消息格式,内置角色、内容类型(文本/图像/视频/音频)等标准化字段,支持开发者快速自定义训练任务;二是兼容Megatron Energon风格的多模态加载方式,可直接适配NVIDIA生态下的大模型训练框架,减少适配成本;三是官方配套提供详细的数据集组成表格,列明各子集的样本量、数据类型和来源处理信息,支持开发者按需选取对应子集开展定向训练,避免数据资源浪费。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)