

随着人工智能技术向生命科学、生态环境等垂直领域的渗透,跨学科研究对高质量、多维度标注的专用数据集需求持续攀升。尤其是在植物功能性状研究、全球生态系统模拟等方向,由于野外采样成本高、数据标注复杂度高,大规模标准化数据集的缺失一直是制约相关研究落地的核心瓶颈。Multimodal Vision Research Laboratory @ WashU(华盛顿大学多模态视觉研究实验室)本次发布的PlantTrait数据集,正是瞄准这一行业痛点推出的公开科研数据资源。该数据集包含带有地理和生物属性标注的图像数据,具体特征包括:图像、经纬度坐标、物种名称、植物功能型(PFT),以及多种植物性状测量值(如高度、比叶面积、叶氮含量、叶面积等)及其上下界范围。数据集分为训练集(222,590个样本)和验证集(84,710个样本),总数据量约346GB,标注维度覆盖了图像、地理、生物属性三大类,能够满足多数交叉研究场景的训练需求,适用于植物物种识别、功能性状预测、生态建模等计算机视觉与生态学交叉领域的研究任务。
从潜在应用场景来看,PlantTrait数据集的价值可覆盖多个科研与产业方向:在基础植物学研究领域,研究人员可基于该数据集训练多模态识别模型,实现对植物物种、功能性状的批量快速判定,大幅降低野外人工采样的人力与时间成本;在生态研究领域,结合数据集中的经纬度坐标与性状参数,可支撑区域植被碳汇能力评估、气候变化下的物种分布模拟、生态系统生产力测算等多个前沿研究方向,为全球生态保护、双碳目标核算等公共政策制定提供数据支撑;在农业与林业应用场景中,该数据集训练的模型也可落地于作物长势监测、林业资源普查、珍稀野生植物排查等实际业务场景。
该数据集的公开上线,也为科研领域的数据要素开放共享提供了典型样本:通过标准化、结构化的科研数据开放,能够有效降低跨领域研究者的获取门槛,加速AI技术与垂直科研领域的融合落地,为数字技术支撑基础科研创新提供了新的路径。
Dataset card内容:
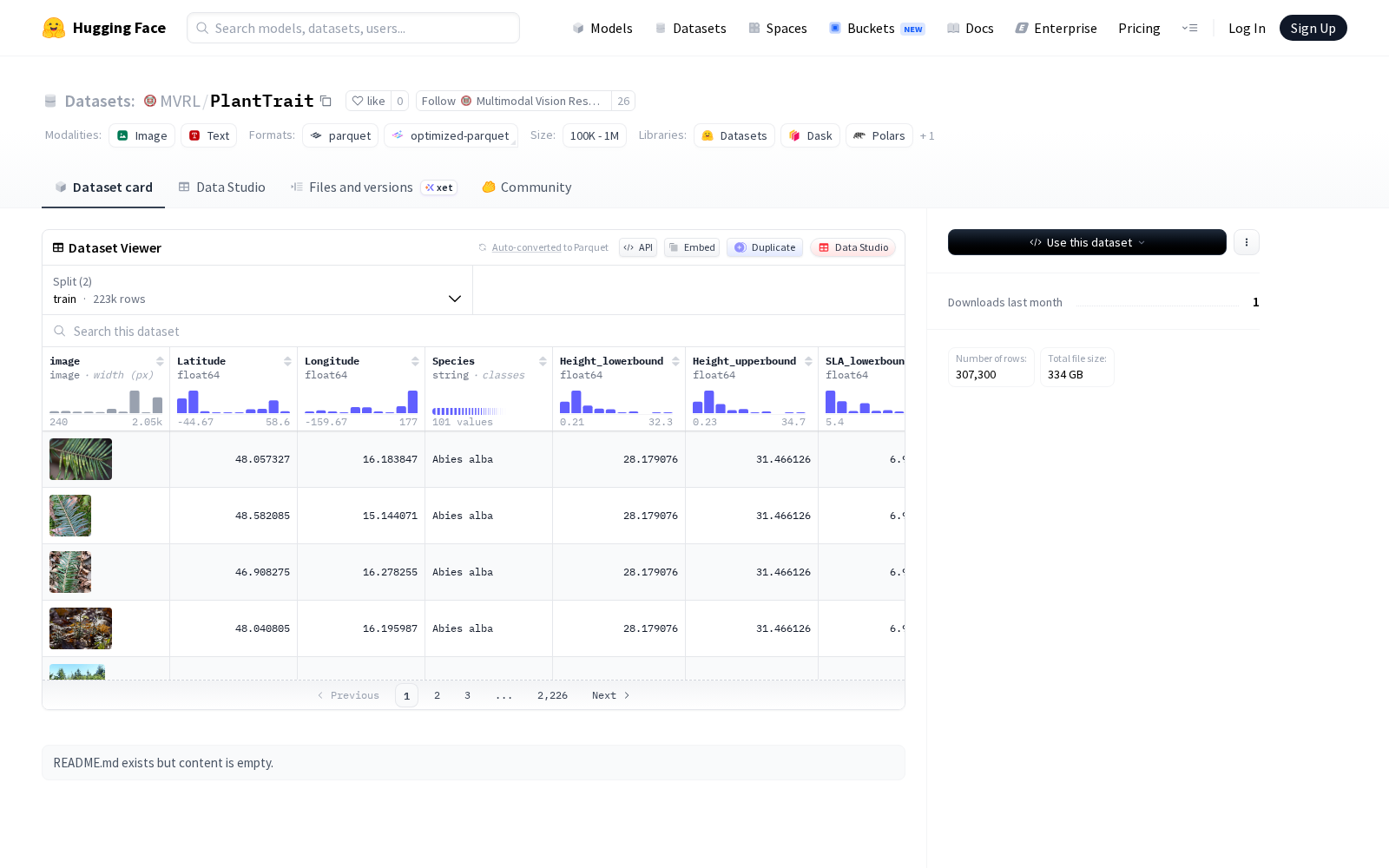
Files and versions内容:



_1769672084863.jpg)