

作为全球顶尖的基础模型学术研究机构,斯坦福大学基础模型研究中心(CRFM)长期主导多语言大模型评测基准、行业数据集的研发工作,其推出的系列评测数据集已成为全球大模型能力评估的核心参考标准。随着多语言大模型向垂直场景落地的节奏加快,小语种、垂直行业的高质量评测数据集缺口持续扩大,其中阿拉伯语作为全球22个国家的官方语言、覆盖超4亿使用人口的主流语种,企业级场景的标准化评测数据集长期处于空白状态,严重制约了阿拉伯语地区大模型产业的商业化落地进程。
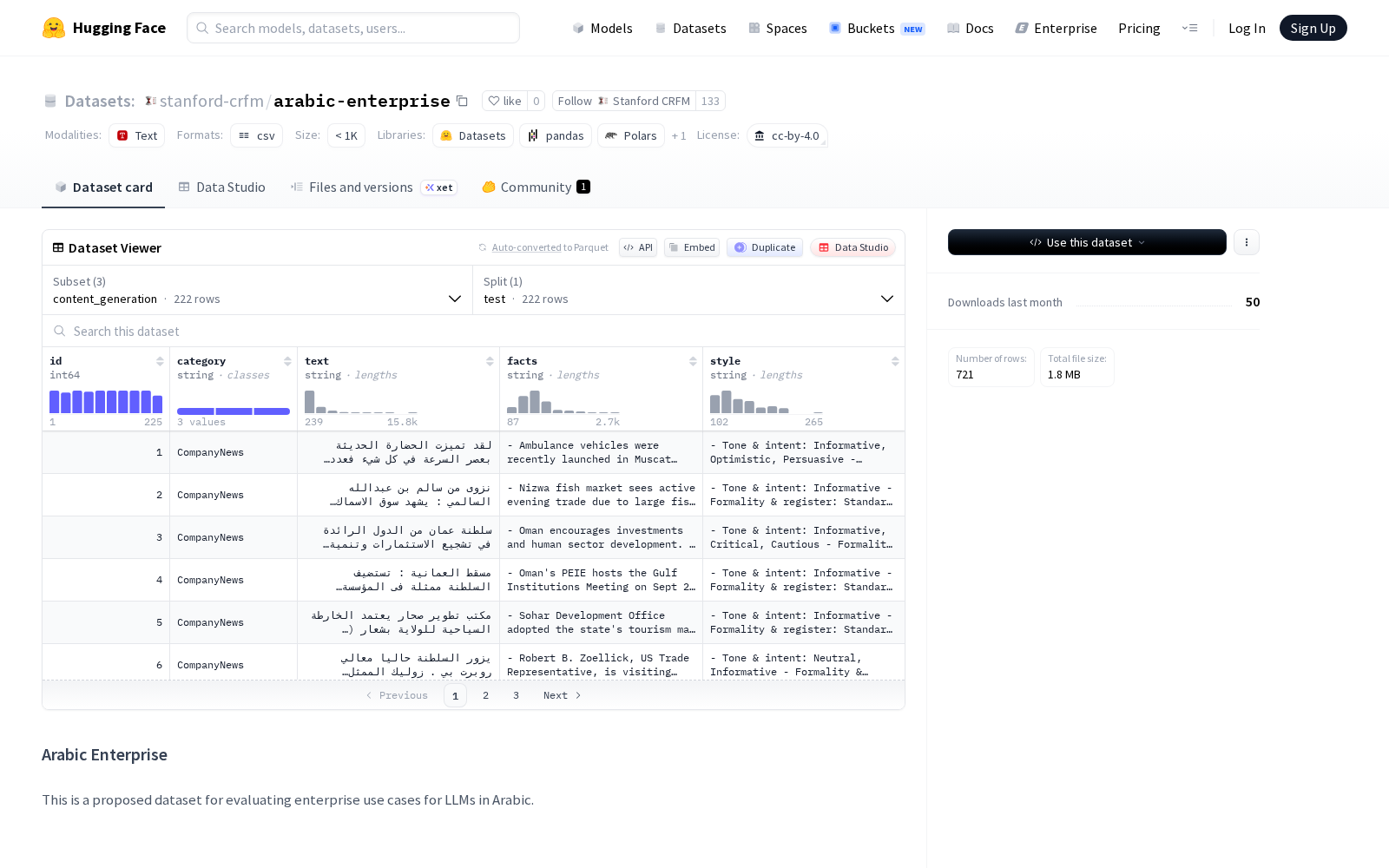
2026年4月30日,斯坦福CRFM正式在HuggingFace平台首发arabic-enterprise阿拉伯语企业级数据集,面向全球开发者开放申请使用。该数据集是全球首个专门用于评估阿拉伯语大型语言模型(LLM)企业级场景适配能力的标准化评测基准,共设置三大核心场景配置:内容生成(content_generation)、金融(finance)和法律(legal),每种配置均配套独立的结构化测试集,存储为可直接调用的CSV文件,方便开发者快速接入评测流程。本次发布的数据集采用cc-by-4.0许可协议,开发者可在合规前提下进行二次开发与商业化使用。查看arabic-enterprise
从应用场景来看,该数据集可覆盖阿拉伯语自然语言处理、企业级文本生成等多个核心领域:在内容生成场景,可用于评测大模型的企业营销素材制作、内部办公文档生成、多语言智能客服应答的准确率与适配性,帮助企业提升数字化办公效率;在金融场景,可支撑阿拉伯语大模型的财报摘要生成、投研内容产出、金融合规问答、客户风险提示文本的能力验证,适配中东、北非等阿拉伯语核心市场的金融机构数字化转型需求;在法律场景,可用于测试大模型的法律文书翻译、跨境合规条款审核、法律咨询应答的专业度,为出海阿拉伯语地区的企业法务数字化建设提供工具支撑。
业内分析指出,本次arabic-enterprise数据集的发布,填补了阿拉伯语大模型垂直企业场景评测基准的空白,进一步完善了全球多语言大模型的评测体系,对推动多语言数据要素价值释放、阿拉伯语地区数字经济发展具有重要的产业参考价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)