

随着多语言大模型研发进入精细化落地阶段,小语种高质量平行语料的稀缺性已成为制约区域AI服务普惠发展的核心瓶颈之一。挪威作为北欧数字经济领先经济体,同时推行布克莫尔(Bokmål)、尼诺斯克(Nynorsk)两种挪威语官方变体,长期以来两类变体之间、变体与英语之间的公开可商用对齐语料供给不足,既影响本土公共服务的多语言适配效率,也限制了挪威与全球英语市场的数字内容互联互通。在此背景下,挪威国家图书馆(Nasjonalbiblioteket)AI实验室于2026年4月30日在HuggingFace平台正式首发maalfrid_parallel(Målfrid平行)数据集,为上述行业痛点提供了标准化数据解决方案。
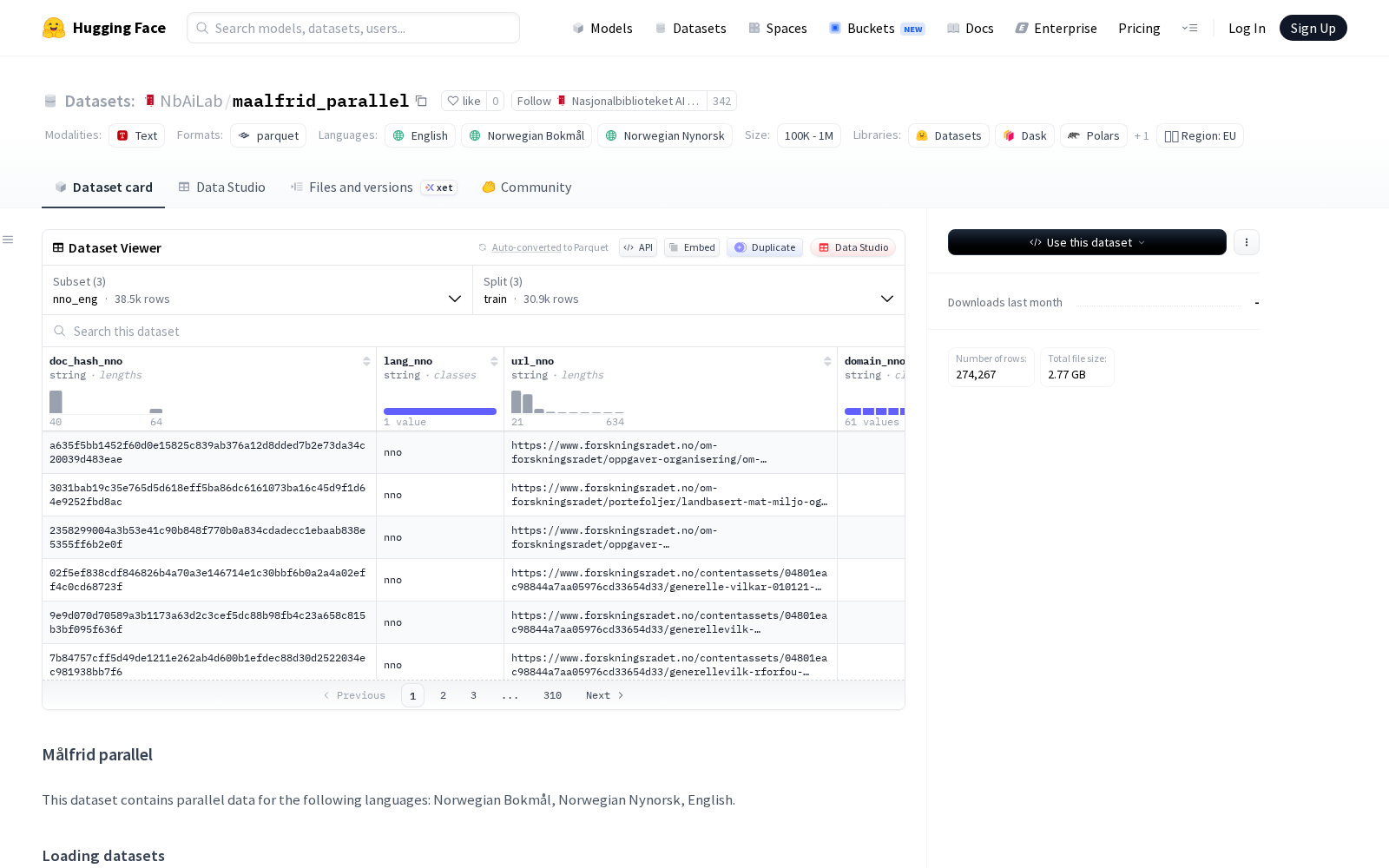
Nasjonalbiblioteket AI Lab本次发布的maalfrid_parallel数据集,覆盖挪威语布克莫尔、挪威语尼诺斯克和英语三类语言的平行对齐数据,共设置三个核心语言对:nob_nno(挪威语布克莫尔与尼诺斯克)、nob_eng(挪威语布克莫尔与英语)和nno_eng(挪威语尼诺斯克与英语)。为适配AI模型研发的通用需求,每个语言对均拆分了训练集、验证集和测试集三个子集,且各子集的源域无重叠,可有效避免模型训练过程中的数据泄露问题,保障后续研发成果的可信度。该数据集原始语料均来源于Målfrid项目爬取的.no后缀挪威政府公开网站内容,该项目本身定位为通过公开互联网内容监测挪威全国语言使用情况,语料的权威性、规范性均有明确保障;对齐环节采用NbAiLab/nb-sbert-v2-base模型及sentence-transformers库实现,其中英语-挪威语平行数据的最小余弦相似度阈值设为0.80,两种挪威语变体之间的平行数据阈值设为0.95,进一步保障了语料对齐的精准度。许可层面,该数据集采用挪威开放政府数据许可(NLOD)2.0版本,合规支持商业与非商业场景的免费使用。
从落地价值来看,该数据集可广泛应用于多个领域:一是可直接用于挪威语两大官方变体的互译模型训练,为挪威本土政府公告、公共服务、教育内容的多版本自动转换提供数据支撑,降低公共服务的语言适配成本;二是可支撑挪威语-英语双向机器翻译模型的优化迭代,助力跨境电商、北欧旅游、北欧学术文献翻译等垂直场景的AI服务能力升级;三是可作为核心资源纳入多语言平行语料库建设,为全球小语种语言资源治理、语言政策研究提供标准化的参考样本。
作为公共部门开放高质量语言数据资源的典型案例,本次数据集的发布既填补了挪威语相关平行语料的公开供给缺口,也为全球公共数据赋能AI产业发展提供了可借鉴的路径:通过对公共领域公开内容的标准化清洗、对齐、分级,形成可复用的基础数据资源,能够有效降低全社会的AI研发门槛,进一步推动语言类数据要素的市场化流通与价值释放。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)