

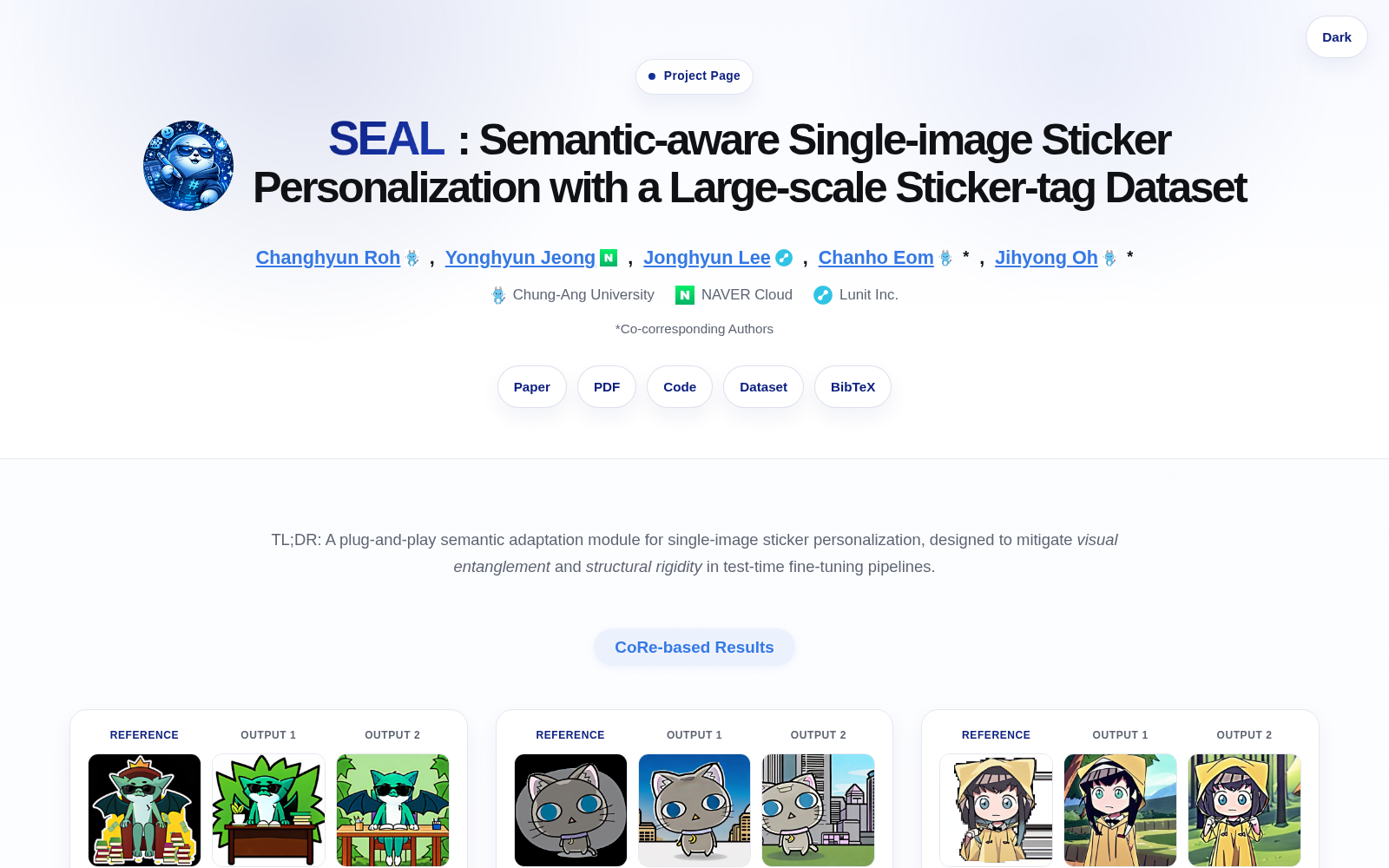
当前AIGC技术正从通用内容生成向垂直场景可控化快速演进,其中个性化贴纸生成作为社交内容、数字营销、创意创作领域的高频需求,长期面临扩散模型单参考图生成时的视觉特征纠缠、结构僵化等痛点,行业始终缺乏专门针对该场景的标准化标注数据集作为算法评估基准。本次StickerBench的发布,恰好填补了这一细分领域的基础数据缺口,为相关技术的落地迭代提供了重要支撑。
据介绍,StickerBench是由中央大学牵头,联合云服务提供商NAVER Cloud、医疗AI科技公司Lunit共同构建的大规模贴纸图像数据集,其核心优势在于搭载了覆盖六大维度的结构化标签标注体系,具体包含外观、情感、动作、镜头构图、风格与背景属性。不同于通用文生图数据集的粗粒度标注逻辑,StickerBench通过丰富的多维度属性注释,构建了固定目标身份下多样化上下文的控制接口,可支持研究人员对单张贴纸个性化生成算法的身份解耦能力、上下文可控性开展系统化、标准化的评估,其标注框架正是针对当前扩散模型在单参考图像场景下的共性技术痛点设计。
从潜在应用方向来看,StickerBench首先可直接服务于贴纸生成类工具的技术研发:包括社交平台的个性化表情包定制工具、电商平台的商品营销贴纸生成模块、内容创作平台的AI装饰素材生产系统等,都可依托该数据集优化算法能力,在精准保留用户指定主体身份特征的前提下,实现动作、情感、风格、背景等属性的灵活可控调整;其次,该数据集的多维度可控标注思路,也可为通用可控文本到图像合成模型的训练、评估提供参考,推动文生图技术进一步满足各类垂直场景的个性化创作需求。
作为AIGC垂直场景下的高质量标注数据集,StickerBench的发布也为数据要素在创意科技领域的落地应用提供了典型样本。当前,高质量标注数据已经成为AI技术迭代的核心生产要素,随着数字内容产业的快速发展,细分场景的专项数据集缺口持续扩大,这类针对性数据集的涌现,不仅能够提升垂直领域AI技术的落地效率,也将进一步完善多模态数据要素市场的精细化布局,助力数字经济创新发展。
详情页内容:



_1769672084863.jpg)