

当前大模型驱动的AI智能体技术正快速从通用对话场景向垂直办公、设备交互场景渗透,但桌面端智能代理的研发长期面临训练数据稀缺的核心痛点:真实用户的计算机环境包含大量个人隐私、商业敏感信息,无法直接用于公开的模型训练与基准测试,无真实隐私风险的合成数据因此成为该领域技术迭代的核心支撑资源。
近日,微软正式对外发布synthetic-computers-at-scale合成计算机环境数据集,该数据集已于2026年5月1日率先在HuggingFace平台上线,面向全球研发人员开放使用。
据介绍,本次发布的数据集包含98个完全虚构的合成计算机环境,每个环境条目对应一个具备独立人设的虚拟用户,覆盖了不同职业背景、使用习惯的用户群体,具体信息包含用户角色、专业背景、月度工作目标、协作方信息、项目组合、个性化文件系统管理策略、完整文件列表及文件关联关系图。为了适配不同角色用户的文件系统异构特性,数据集没有采用强制统一的存储schema,而是通过JSON编码字符串存储非ID列数据,完整保留了不同用户场景下的嵌套结构特征。其生成流程经过了多轮逻辑校验,从初始角色采样、用户资料扩展,到月度计划制定、项目组合与文件系统策略具象化,再到最终文件列表与关系图生成,全链路确保数据逻辑的自洽性。
从应用方向来看,该数据集主要面向三大研发场景开放:一是桌面代理的基准测试,可用于评估AI智能代理对不同用户计算机环境的适应能力、操作准确性,为各类办公AI助手、设备智能管控系统的能力测评提供标准化参考;二是长期任务规划研究,可用于训练智能代理理解跨月维度的复杂项目目标,拆解多步执行任务,跟踪不同项目的进度与产出;三是文件组织推理的合成数据训练,帮助智能代理快速理解不同用户的文件分类逻辑,实现文件检索、自动整理、关联推荐等功能的优化。
需要注意的是,该数据集所有角色、项目、文件均为虚构生成,不存在任何真实用户隐私泄露风险,当前98台规模的版本主要用于技术评估,同时可作为种子数据支撑更大规模合成计算机环境的生成。数据集采用MIT许可证发布,商业使用门槛极低,方便各类研发团队二次开发与落地应用。作为合成数据在智能体交互领域的典型落地成果,该数据集的发布也为数据要素市场中“合规场景化合成数据”的研发与应用提供了参考样本,将进一步推动AI智能体在办公场景的落地迭代。
查看synthetic-computers-at-scale
Dataset card内容:
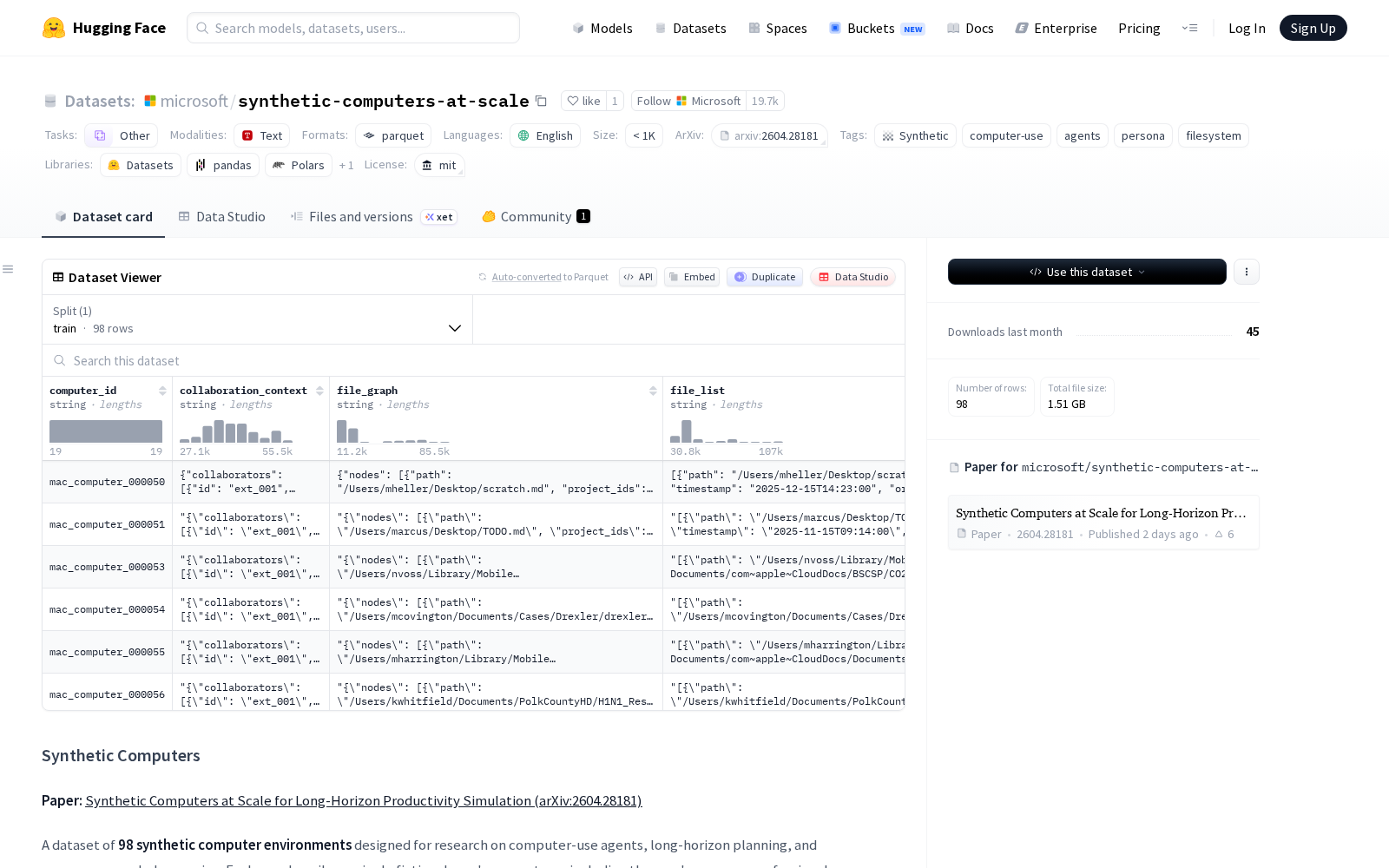
Files and versions内容:



_1769672084863.jpg)