

随着全球客服产业数字化转型加速,语音识别(ASR)、大模型对话系统等AI技术已广泛渗透到运营商、金融、零售等多个领域的客服场景中,但长期以来,面向真实客服对话的高质量多口音评测数据集缺口,始终是制约长时对话ASR系统准确率提升、智能客服多区域适配的核心痛点。
全球领先的多语言语音技术服务商AppTek.ai于2026年4月30日在预印本平台arXiv正式首发AppTek Call-Center Dialogues英语语音识别评测数据集,为上述行业痛点提供了新的解决方案。
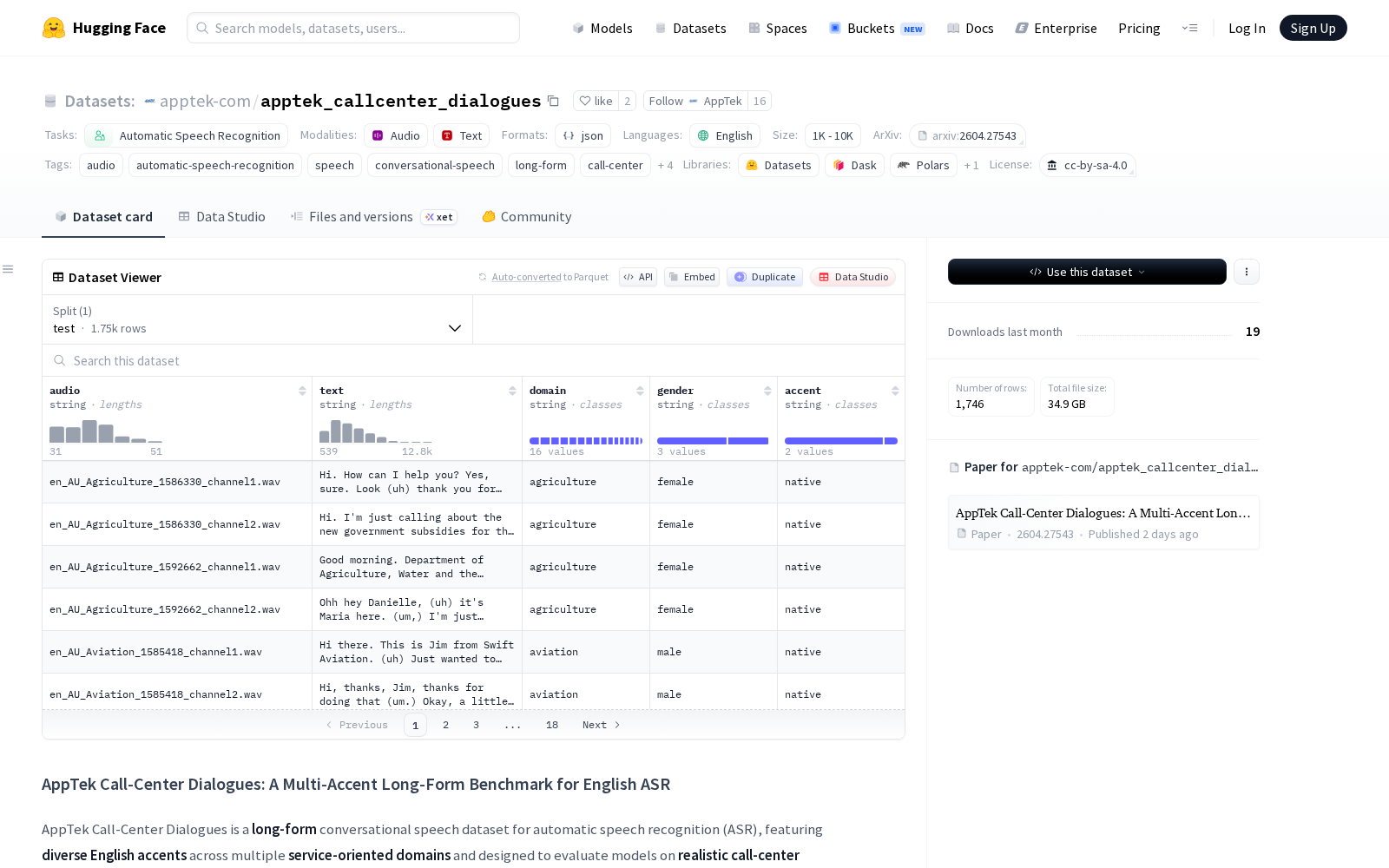
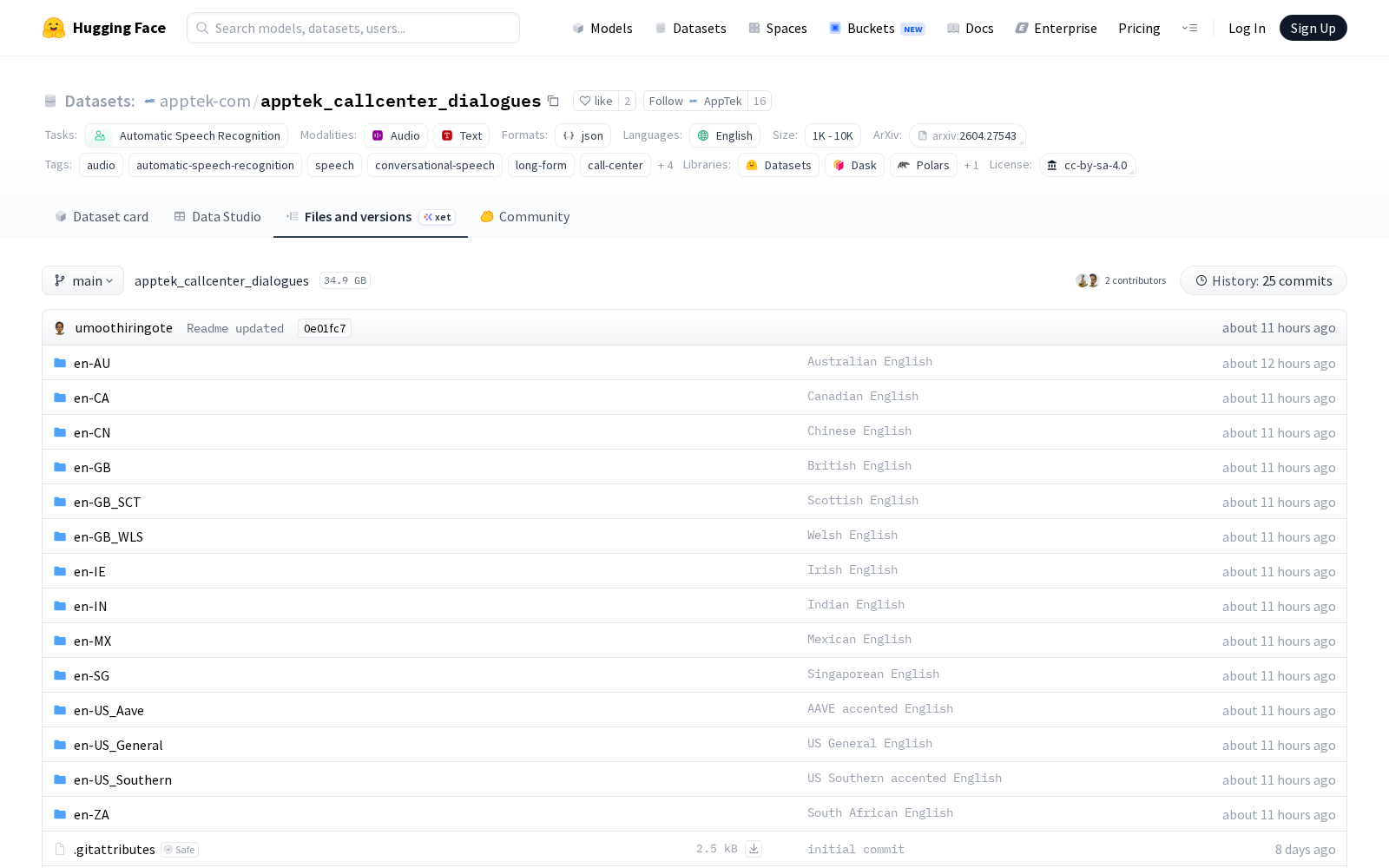
据了解,该数据集由AppTek.ai团队自主构建,全部采用自发性角色扮演的真实客服对话素材,覆盖14种全球主流英语口音,总时长达到128.6小时,共收录156名不同身份说话者的对话内容,覆盖电商售后、金融理赔、电信业务咨询等16个高频客服服务场景。所有数据均经过专业人员转录和多轮严格质量审核,最大程度保留了真实对话中的停顿、重复、口误等不流畅现象,以及各服务领域的专有词汇,与实际客服场景的语音特征高度匹配。
该数据集的核心设计目标,正是解决当前通用ASR评测数据集普遍存在的场景单一、口音标准化、对话结构化等不符合真实应用环境的问题,为长时对话ASR系统在多样化口音、非结构化真实交互场景下的性能评测提供标准化的基准工具。
从落地价值来看,该数据集可广泛应用于多个领域:在语音技术研发端,可作为ASR系统的通用评测基准,帮助技术团队优化多口音识别、长时语音转写的准确率,尤其适用于面向全球市场的语音交互产品研发;在客服数字化升级端,该数据集可用于智能客服系统的语义理解模块训练,提升不同口音用户诉求的识别准确率,也可用于客服对话质量分析、用户情绪识别、坐席服务能力优化等场景,帮助企业降低客服运营成本、提升用户服务体验。
查看AppTek Call-Center Dialogues
作为AI产业的核心生产要素,高质量垂直场景标注数据集的供给能力,直接决定了AI技术落地的效率与效果。此次AppTek.ai发布的客服对话数据集,填补了全球多口音真实客服场景ASR评测数据集的空白,对于推动语音交互技术在服务产业的规模化落地、完善全球数据要素市场的垂直场景数据集供给体系,均具有重要的行业参考价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)