

在全球语音交互技术快速落地的当下,中文、英语等高资源语种的语音训练数据供给已相对充足,但挪威语等北欧小语种的高质量开源训练资源始终存在较大缺口,成为制约区域数字化服务、无障碍设施、跨境智能交互等场景落地的核心瓶颈。作为挪威国家级公共文化与数字资源研究机构,Nasjonalbiblioteket(挪威国家图书馆)AI Lab长期聚焦北欧语言数字资产的整理与开放,此前已围绕挪威语语音、文本资源发布多组开源数据集,为北欧语言AI研发提供了核心公共数据支撑,此次推出的优化版本正是针对原有TTS数据集的行业共性反馈完成的定向升级。
Nasjonalbiblioteket AI Lab本次发布的数据集nst_tts_dataset_trimmed,是对原有`NbAiLab/nst_tts_dataset`完成边缘静音修剪后的优化版本,专门面向挪威语文本转语音(TTS)系统训练场景打造。该数据集包含`metadata.jsonl`标注文件和修剪后的`.wav`音频文件,修剪操作仅针对每个音频片段的首尾冗余静音部分,完整保留了音频内部的自然语流停顿。据官方披露的参数,本次优化共修剪了`5363`个音频文件,总计移除静音时长达到`12302.27`秒,平均每个片段移除`2.193`秒冗余内容,单个片段最高移除静音时长达到`5.154`秒。其修剪策略经过多轮测试调整:采用`20.0 ms`帧大小实现对语音边界的精准识别,设置`120.0 ms`最小检测语音跨度避免截断有效发音,同时分别预留`80.0 ms`前导语音填充和`120.0 ms`后导语音填充,在移除无效静音的同时最大程度保留口语表达的自然节奏。该版本的核心价值在于为TTS系统训练提供低冗余度的音频数据,既能够减少模型训练阶段的算力浪费、压缩训练周期,也能避免合成语音出现首尾空白、断句异常等问题,直接提升最终输出语音的流畅度与自然度。
从应用方向来看,该开源数据集可广泛应用于多个挪威语语音交互场景的技术研发:包括面向本土市场的智能客服、智能家居语音助手开发,公共服务领域的自动语音播报、政务服务语音交互系统搭建,无障碍场景的挪威语屏幕阅读器、有声读物自动生成工具研发,以及跨境服务中的挪威语多语种交互模块训练等。对于全球从事小语种语音AI研究的机构和开发者而言,这一经过预处理的高质量数据集可直接接入训练流程,大幅降低数据预处理环节的人力与时间成本。
此次数据集的开放也是公共文化机构释放数字资源价值、赋能数据要素市场建设的典型实践。当前全球多语种AI训练数据的稀缺性持续凸显,由国家级公共机构主导的开源数据供给,既能够保障训练数据的合规性与标注质量,也能有效降低中小研发团队的技术创新门槛,为区域数字经济的均衡发展提供基础支撑。
Dataset card内容:
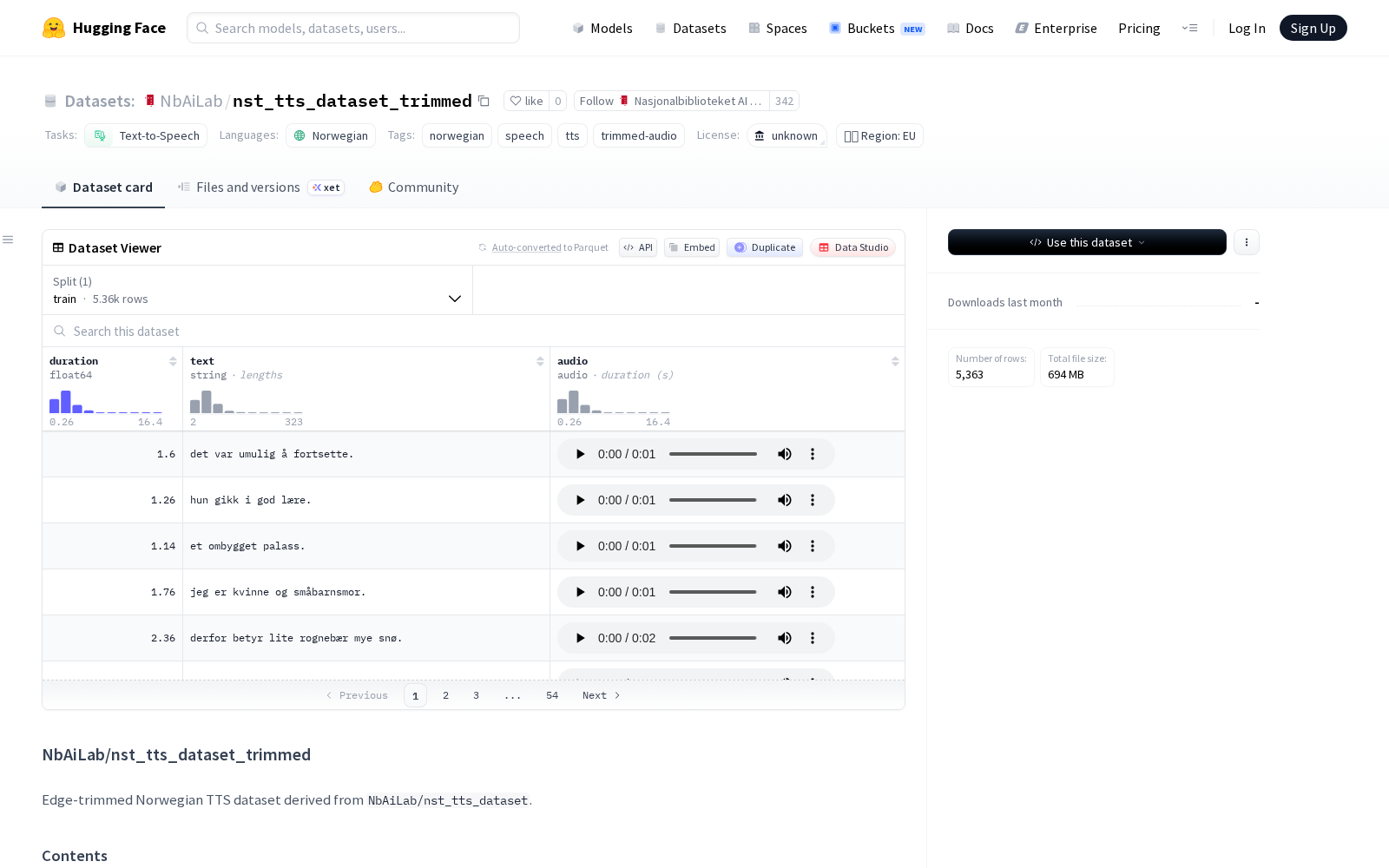
Files and versions内容:



_1769672084863.jpg)