

当前全球具身智能产业进入落地攻坚期,机器人在非结构化场景下的精细化操作能力、动态环境感知能力成为技术迭代的核心方向,而高质量、多模态的场景化训练数据集,是支撑相关算法研发、模型迭代的核心基础设施。此前公开市场中的机器人操作数据集普遍存在模态覆盖不全、视角单一、动作维度标注不足等问题,大幅提升了中小研发团队的技术准入门槛。
近日,机器人技术研发商L7-Robotics正式发布由LeRobot打造的so101_3cam_red_cube_white_bowl_v1数据集,该数据集已于2026年5月4日首发上线全球知名AI开源社区HuggingFace,面向全球研发团队开放使用。
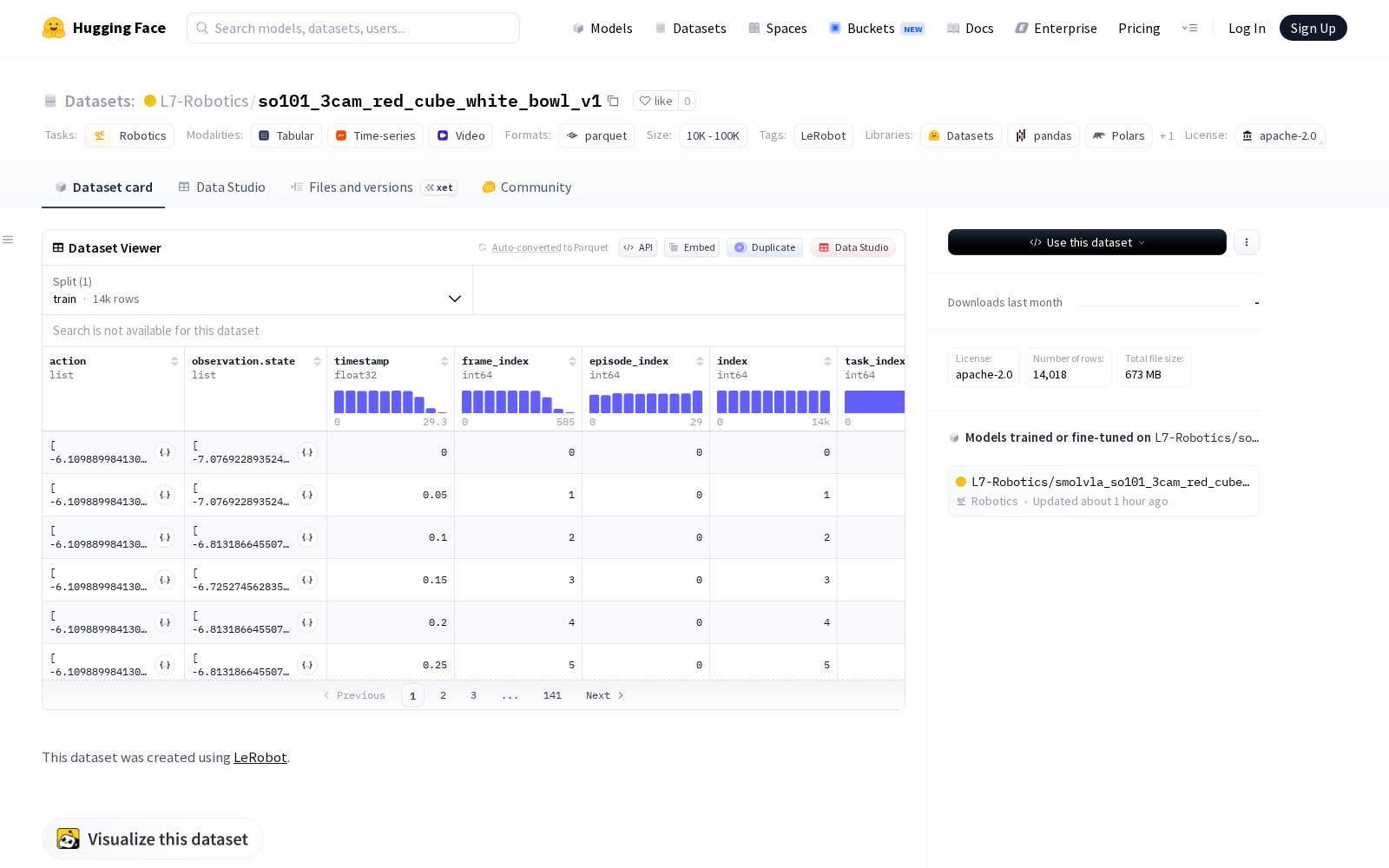
据官方披露,本次发布的数据集围绕典型桌面操作任务设计,共包含30个完整操作情节、累计14018帧标注数据,覆盖三大类核心数据维度:一是机器人本体动作数据,包含肩部、肘部、腕部等核心关节的实时位置信息,完整还原机械臂操作过程中的关节协同运动逻辑;二是机器人观察状态数据,与动作数据形成对应标注,可支撑动作执行效果的校验与优化;三是多视角视觉数据,同步收录顶部、后部、腕部三路视频流,分辨率为480x640,帧率达20fps,可同时覆盖全局场景状态、操作对象动态变化、末端执行器近距离操作细节三类视觉信息,解决了单视角数据普遍存在的遮挡、信息缺失问题。数据集整体采用更适合AI训练场景的parquet列式存储格式,结构化数据文件大小为100MB,视频文件总大小为200MB,较低的存储门槛也方便中小研发团队快速下载部署测试。
从应用价值来看,该数据集可广泛应用于机器人动作控制、多视角环境感知两大核心研发方向:在动作控制领域,研发团队可基于关节与动作的联动标注数据,训练机械臂的抓取、摆放、分拣等精细化操作策略,提升工业产线分拣、家政服务等场景下的机器人操作精度与稳定性;在多视角环境感知领域,依托三路不同维度的视觉数据,可优化机器人的动态环境建模、操作目标识别、遮挡场景下的目标追踪等算法能力,适配复杂非结构化场景的感知需求;此外,该数据集还可作为具身智能大模型的小样本测试基准,验证多模态大模型在实体操作任务中的推理准确性与落地可行性。
查看so101_3cam_red_cube_white_bowl_v1
Dataset card内容:
Files and versions内容:
业内分析指出,本次L7-Robotics开放的多模态机器人操作数据集,填补了桌面操作场景下“动作-视觉”联动标注数据集的供给空白,不仅降低了具身智能领域的研发准入门槛,也为全球技术团队提供了统一的算法测试基准,对推动通用机器人技术的快速迭代、加速具身智能产业落地进程具有积极意义。



_1769672084863.jpg)