

随着大语言模型技术向语义网、知识图谱等领域渗透,基于能力问题(Competency Questions, CQs)自动生成本体的技术路线,正在成为降低本体构建门槛、加快垂直领域知识语义化建模的核心方向。但长期以来,该领域研究缺乏统一的跨领域评估基准,不同团队的算法效果难以横向对比,成为制约技术规模化落地的重要瓶颈。
作为全球深耕本体工程、语义网技术研究的顶尖学术团队,Ontology Engineering Group本次发布的CQ2Onto,正是针对这一行业痛点推出的专用基准数据集,也是全球首个同时覆盖术语提取、完整本体生成两类任务的多领域评估资源。
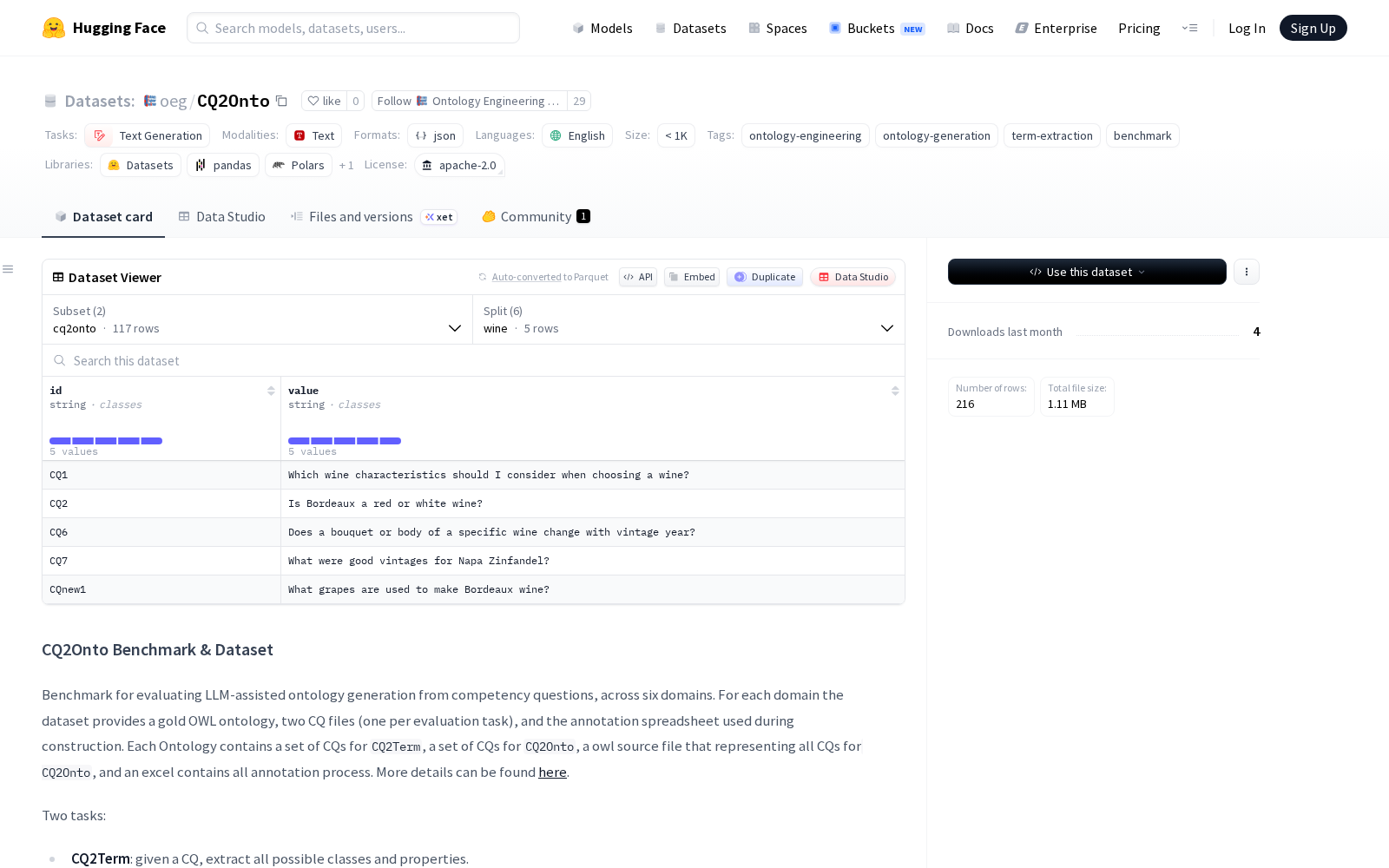
CQ2Onto定位为评估大语言模型(LLM)辅助下能力问题生成本体效果的基准数据集,共覆盖Wine、AWO、ODRL、Water、VGO、SWO六个不同规模的垂直领域。针对每个领域,数据集均配套了黄金标准的OWL本体、对应两类评估任务的CQ文件,以及完整构建过程中的注释表格,确保评估结果的可追溯性与客观性。
该数据集设置两大核心评估任务:其一为CQ2Term任务,要求算法针对给定的单个能力问题,提取所有对应的类与属性,对应术语提取类技术的评估需求;其二为CQ2Onto任务,要求算法针对给定的一组能力问题,生成完整的OWL格式本体,对应本体自动生成类技术的评估需求。数据集文件包含JSON格式的CQ列表、RDF/XML格式的OWL本体文件,可直接适配主流大模型训练与评估框架,适配本体工程、本体生成、术语提取等多类任务的研究与测试需求。
从应用价值来看,CQ2Onto可在多个场景释放潜在价值:科研院所可依托该数据集统一比对不同大模型、不同算法在本体生成任务上的表现,降低自定义数据集的研发成本;企业级知识图谱团队可参考该数据集的任务框架,训练面向制造、医疗、金融等垂直领域的专用本体生成工具,加快内部知识资产的语义化治理进程;语义搜索、智能客服等领域的技术团队,也可借助CQ2Term任务基准测试术语提取算法的准确率,优化专业领域的语义理解效果。
当前全球数据要素市场建设正进入深水区,跨机构、跨领域的数据流通共享对语义互操作能力提出了更高要求,而标准化、高质量的本体正是实现语义互操作的核心底座。CQ2Onto这类基准资源的发布,将进一步推动大语言模型与本体工程技术的融合创新,为知识资产化、数据语义化治理等数字经济核心场景提供底层技术支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)