

LAION eV本次发布的数据集voiceclap-data,VoiceCLAP 数据集是一个用于训练音频和密集字幕混合模型的数据集,支持音频分类和特征提取任务。数据集包含多个子集,如 Emolia、LAIONs Got Talent、Majestrino 等,每个子集都有不同的来源和特点。数据以 WebDataset 格式存储,每个样本包含一个 48 kHz 单声道音频文件(.flac)和一个 JSON 文件(包含字幕和元数据)。字幕和属性注释由音频感知的 LLM 自动生成,包括情感、音色、韵律等标签。数据集规模在 1B 到 10B 之间,适用于多语言和语音相关的研究。使用该数据集时需注意伦理问题,避免用于可能重新识别、分析或监视说话者的任务。数据集采用 CC-BY-4.0 许可证,部分子集可能继承上游来源的许可条款。
Dataset card内容:
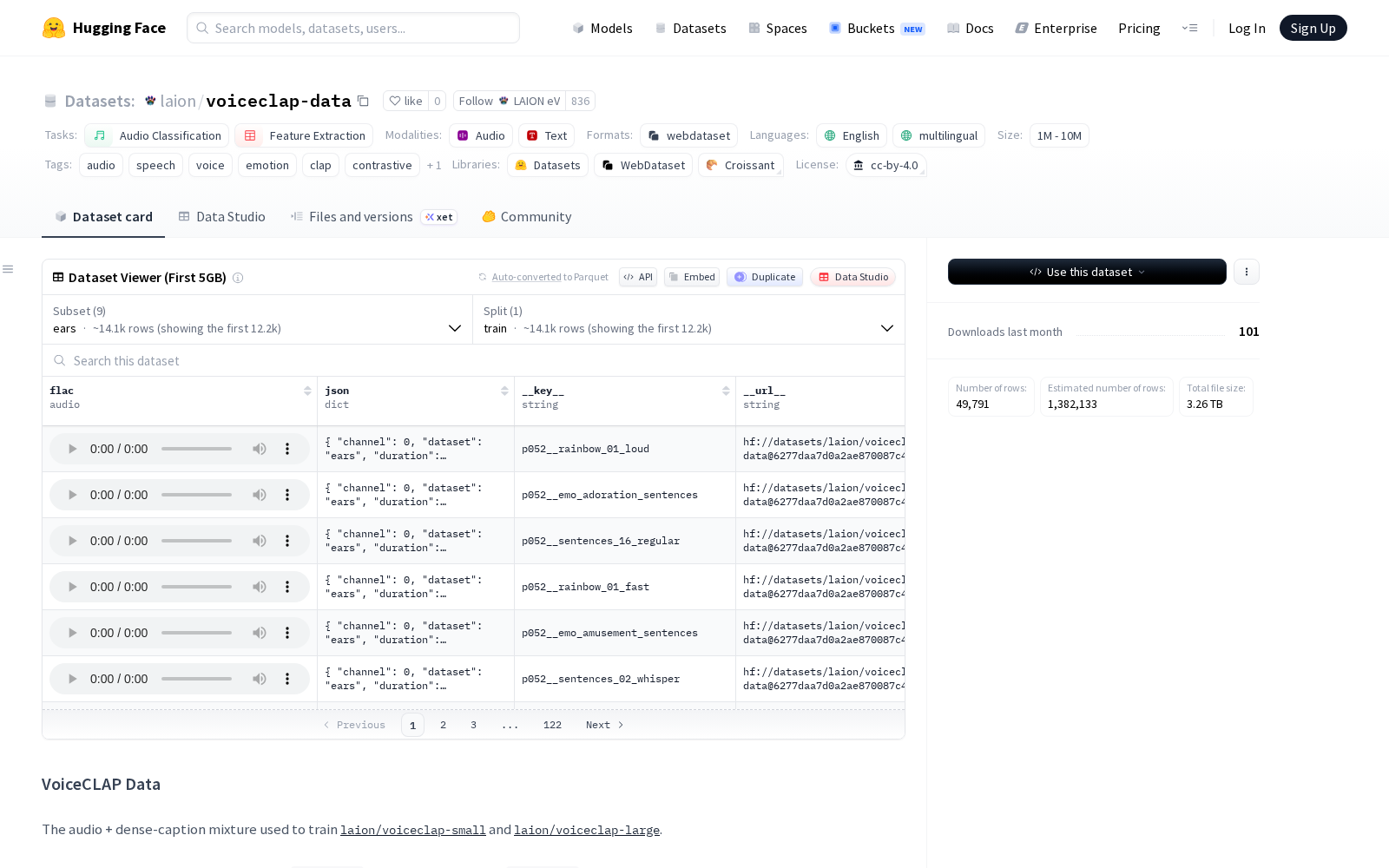
Files and versions内容:



_1769672084863.jpg)