

随着代码大模型在智能开发工具领域的规模化应用,AI生成代码的“幻觉问题”已经成为制约工具落地、影响开发效率的核心痛点——很多大模型输出的代码语法通顺、逻辑看似合理,实际运行时却会出现各类报错,甚至隐含安全漏洞,而行业此前一直缺乏覆盖多语言、针对知识级幻觉的标准化评测基准。本次微软发布的delulu-fim-benchmark数据集,正是瞄准这一行业空白打造的专业评测工具。
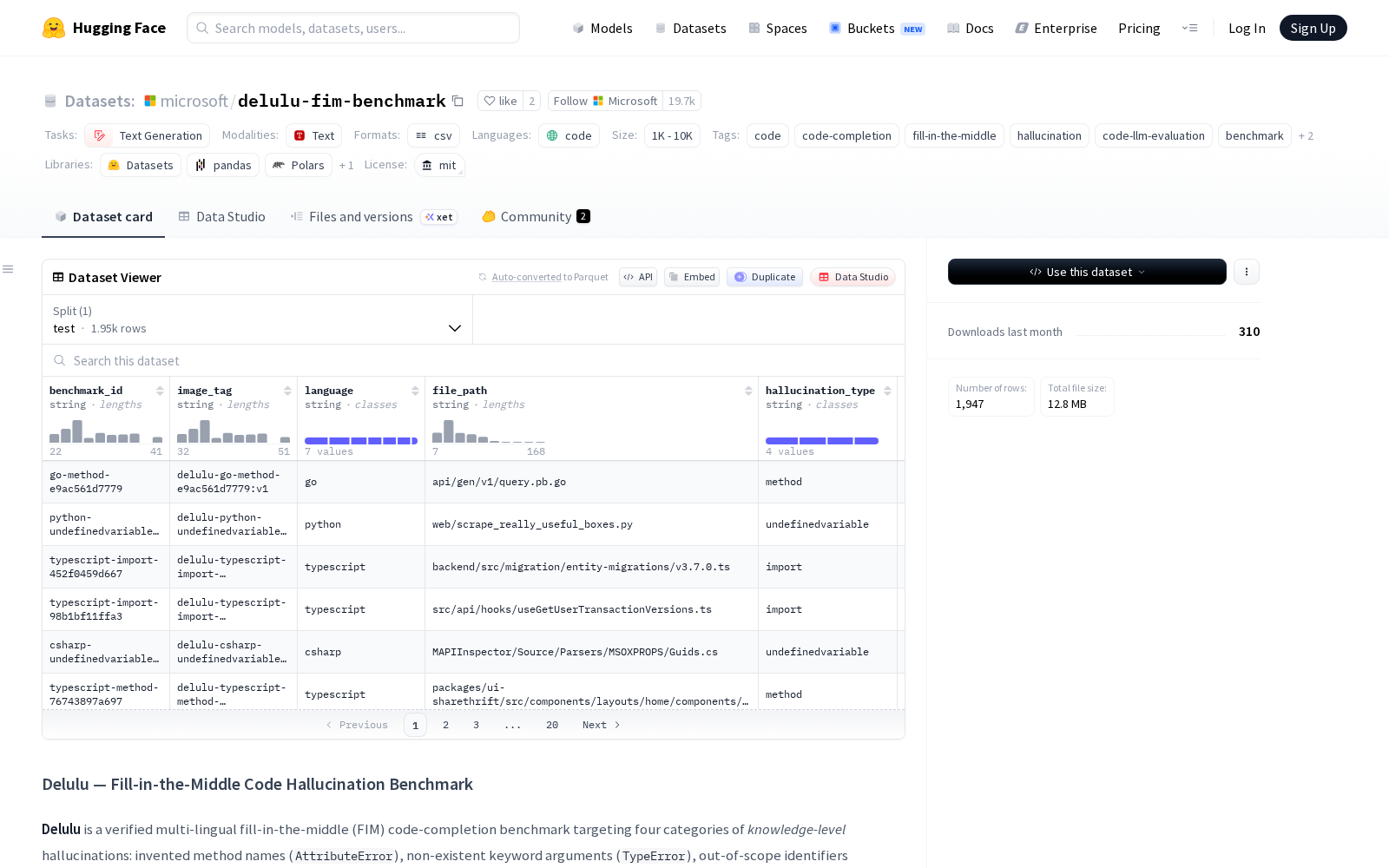
作为经过多重验证的多语言填充中间(FIM)代码补全基准数据集,Delulu核心测试维度覆盖四类开发者日常调试中最常遇到的知识级幻觉场景:虚构的方法名(对应运行时`AttributeError`报错)、不存在的关键字参数(对应`TypeError`报错)、超出范围的标识符(对应`NameError`报错)和不存在的导入(对应`ImportError`报错),精准对齐实际开发中的真实报错场景。
该数据集共包含1947个经过严格核验的测试样本,覆盖Python、TypeScript、Java、C#、Go、Rust、C++共7种主流编程语言,能够满足不同技术栈代码大模型的评测需求。为了保障测试结果的准确性,每个样本都配有一个经过验证的正确“黄金”补全样本和一个典型“幻觉”补全样本,两类样本均通过Docker容器中的实际运行验证,同时经过三名资深开发专家的交叉审查,最大程度避免样本本身的偏差。
官方明确标注该数据集仅用于测试目的,不建议用于模型微调,避免数据泄露导致后续评测结果失真。从应用场景来看,该数据集既可以用于代码补全大模型的生成效果基准评测,帮助厂商定位模型在不同语言、不同幻觉类型上的能力短板,优化模型训练策略;也可以用于幻觉检测工具、代码验证器的能力评估,为AI代码审计、智能调试工具的迭代提供标准化测试依据,同时也能为科研领域的大模型幻觉治理研究提供统一的参照数据集。当前垂直领域高质量评测数据集是AI产业的核心稀缺资源,该数据集的发布也将推动代码大模型从“能写代码”向“写对代码”升级,助力AI开发工具的商业化落地,进一步降低软件开发行业的整体试错成本。数据集的结构包括每个样本的元数据、补全文本、错误消息和许可证信息,适用于代码补全模型的生成评估以及幻觉检测和验证器评估。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)