

当前,自然语言处理技术的研发与应用多集中在现代通用语料场景,针对19世纪及之前的小语种历史语料的高质量标注数据集供给长期不足,既制约了历史语言学的定量研究深度,也限制了面向历史文献的NLP模型开发效率。近日,丹麦奥胡斯大学人文计算中心(Center for Humanities Computing Aarhus)联合奥尔堡大学ENO团队开发的hist-dk-pos数据集于2026年5月8日正式首发上线HuggingFace,为上述领域的研究提供了全新的高质量标注语料支撑。
据介绍,本次发布的hist-dk-pos数据集原始文本抽取自Press-and-Plot数据集(索引10)收录的1824年丹麦出版的历史报纸、小说文本,通过随机抽样选取典型语句构建样本库。标注流程上,团队采用「自动预标注+双人人工校验+最终裁定」的多轮质量管控机制:首先通过SpaCy的丹麦语词性标注器完成自动预标注,再由两名专业标注员独立完成人工修正,最终的标注差异由首位标注员完成终裁,确保标注准确率达到学术研究级标准。目前该数据集由奥胡斯大学人文计算中心GoldenMatrix团队全程策划,共包含704个训练样本,每个样本设置单词(word)、词性标签(pos)两大核心字段,语言为1824年标准丹麦语,采用CC0许可协议开放,支持商业与非商业场景的免费使用。
从应用场景来看,该数据集可广泛覆盖多领域研究需求:在历史语言学领域,研究人员可基于该数据集开展19世纪丹麦语的词性演变、语法规则变迁、词汇语义演化等研究,对比现代丹麦语的语言特征,梳理丹麦语近200年的发展脉络;在自然语言处理领域,可作为训练数据集,开发面向19世纪丹麦历史文献的词性标注模型、文本识别模型,助力丹麦近代历史报纸、手稿、档案等非结构化文献的数字化转写与结构化处理,提升历史文献的挖掘效率;在社会文化研究领域,通过对标注语料的语义分析,可还原1824年丹麦社会的公共议题、文化特征、民众生活风貌,为近代丹麦社会史、传媒史、文学史的研究提供定量分析支撑。
作为小语种历史标注语料的代表性成果,hist-dk-pos数据集的开放,填补了19世纪丹麦语标注语料的供给空白,也为全球人文领域数据集的开发、标注、开放提供了可参考的质量管控范式。近年来,随着全球数字人文领域的快速发展,高质量人文标注数据集已经成为支撑跨学科研究的核心数据要素,本次数据集采用CC0协议开放,进一步降低了全球相关领域研究人员的获取门槛,对推动数字人文交叉学科发展、激活历史文化数据要素价值具有积极意义。
Dataset card内容:
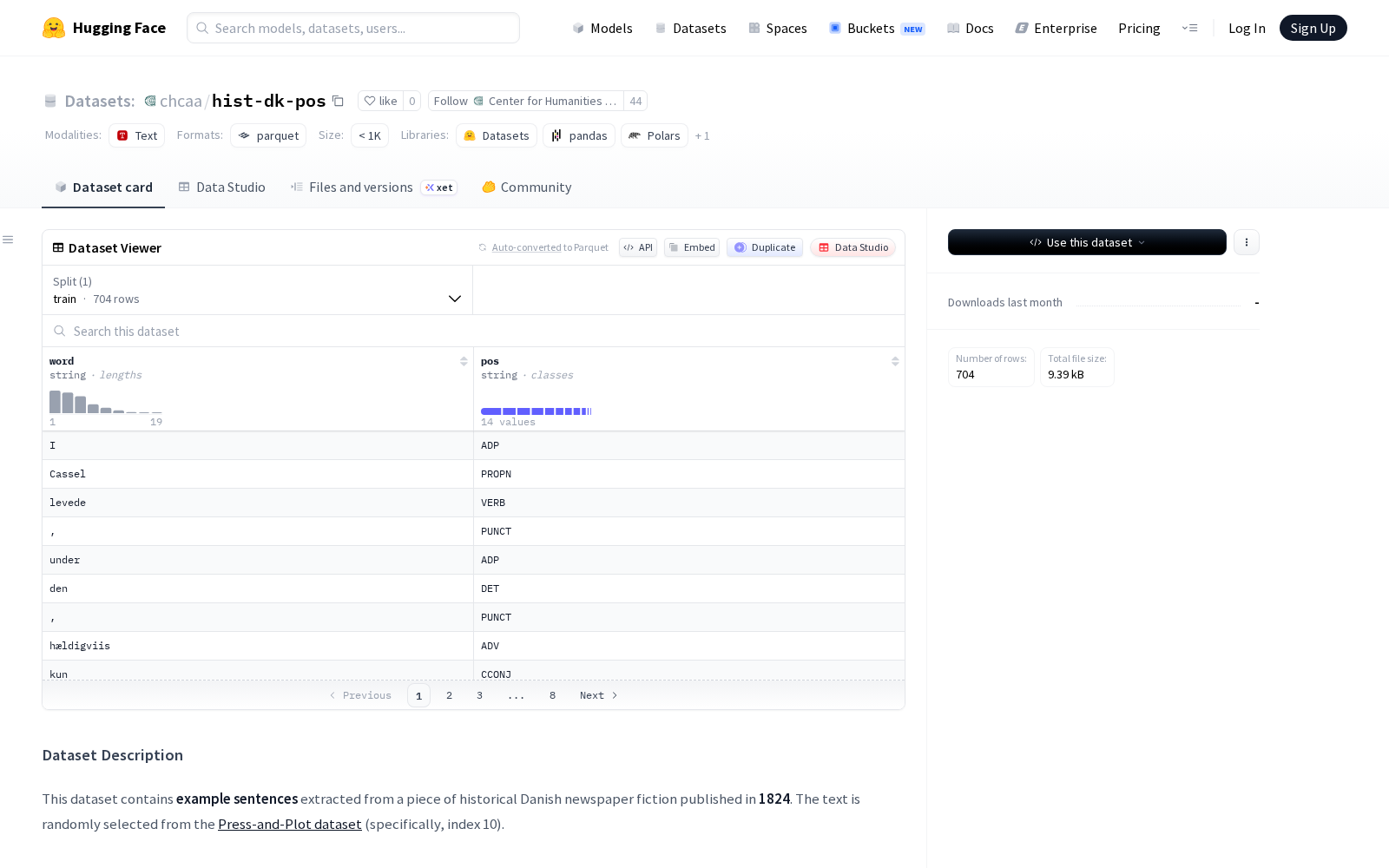
Files and versions内容:



_1769672084863.jpg)